
程序 = 数据结构 + 算法
参考资料:点击此处
递归
定义
若一个对象部分地包含它自己,或用它自己给自己定义,则称这个对象是递归的;若一个过程直接或间接地调用自己,则称这个过程是递归的过程。
| 递归 | 内容 |
|---|---|
| 三种情况 | 定义是递归的 |
| 数据结构是递归的 | |
| 问题的解法是递归的 | |
| 特点 | 递归至少存在一个出口 |
| 函数内部自己调用自己 |
问题举例
阶乘
阶乘的定义:
$$ n! = \left\{ \begin{array}{c} 1, & n = 0 \\ n \cdot (n-1)!, & n \geqslant 1 \end{array} \right.$$可知阶乘的定义是递归的。
1long long Factorial(long long n) {
2 if (n == 0) {
3 return 1;
4 }
5 else {
6 return n * Factorial(n-1);
7 }
8}
查找链表的元素
定义链表:
1struct Node {
2 ElemType data;
3 Node *next;
4};
可知链表的数据结构是递归的。
1void Search(Node *f, ElemType e) {
2 if (f != NULL) {
3 if (f->data == x) {
4 printf("%d\n", f->data);
5 }
6 else {
7 Search(f->next, e);
8 }
9 }
10 return;
11}
汉诺塔问题
问题概述:假设有3个分别命名为x,y,z的塔座,在塔座x上插有n个直径大小各不相同、依次编号为1,2,3,…,n的圆盘。现要求将x塔座的n个圆盘移动到z塔座上且按同样的顺序堆叠。圆盘移动时遵循以下规则:
- 每次只能移动一个圆盘。
- 圆盘可以放在x,y,z的任意塔座上。
- 任何时刻都不能将一个较大的圆盘放在较小的圆盘之上。
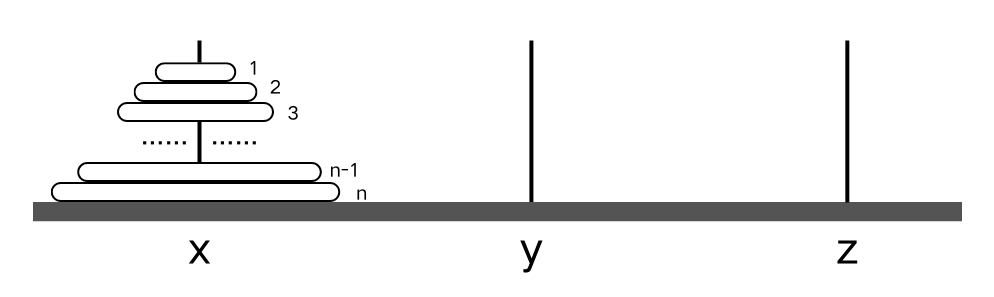
因此,汉诺塔问题的解法是递归的。
1void hanoi(int n, char x, char y, char z) {
2 if (n == 1) {
3 move(x, 1, z); // 将编号为1的圆盘从x移到z
4 }
5 else {
6 hanoi(n-1, x, z, y); // 将x上编号为1到n-1的圆盘移到y,z作为辅助塔
7 move(x, n, z); // 将编号为n的圆盘从x移到z
8 hanoi(n-1, y, x, z); // 将y上编号为1到n-1的圆盘移到z,x作为辅助塔
9 }
10}
快速幂
参考:洛谷P1226题解
让计算机求出 $a^b$,暴力相乘的话,电脑要计算 $b$ 次。用快速幂,计算次数在 $\mathrm{log}_{2} b$ 级别,很实用。
原理
- 如果将 $a$ 自乘一次,就会变成 $a^2$。再把 $a^2$ 自乘一次就会变成 $a^4$,然后是 $a^8$……自乘 $n$ 次的结果是 $a^{2^n}$。
- $a^x \cdot a^y = a^{x+y}$。
- 将 $b$ 转化为二进制看一下:比如 $b=(11)_{10}=(1011)_2$,从左到右,这些 1 分别代表十进制的 8,2,1。可以说 $a^{11}=a^8 \cdot a^2 \cdot a^1$。
为什么要这样表示?
因为在快速幂的过程中,我们会把 $a$ 自乘为 $a^2$,然后 $a^2$ 自乘为 $a^4$,以此类推,像上面第一条说的。
示例:已知 $a$,并且 $b=11$。求 $a^b$。
- 以电脑视角稍稍观察一下 $b=11$,二进制下是 $b=1011$。
- 制作一个
base。现在base = a,表示的是 $a^1=a$,base会变。制作一个ans = 1,准备用来做答案。 - 开始循环
| 操作 | |
|---|---|
| 循环一 | 看 $b$(二进制)的最后一位是1吗?是的。这代表 $a^{11}=a^8 \cdot a^2 \cdot a^1$ 中的 $\cdot a^1$ 存在。所以ans ∗= base。 因为1(二进制)的前面几位全部都是0,所以只有 $b$ 二进制最后一位是1时,b & 1才会返回 1。挺巧妙的,并且很快。 然后base努力上升,它通过自乘一次,使自己变成 $a^2$ 。同时 $b$ 把(二进制的)自己每一位都往右移动了。原来的最后第二位,变成了最后第一位!$b=(101)_2$。 |
| 循环二 | 再看看b,最后一位还是1。这说明有 $ \cdot a^2$,ans ∗= base。base继续努力,通过 base ∗= base让自己变成了 $a^4$。然后 $b$ 也右移一位。$b=10$ |
| 循环三 | 可是 $b$ 的最后一位不再是1了,说明不存在 $\cdot a^4$。base自我升华,达到了 $a^8$。且 b>>=1。这一步中,答案没有增加,可是毕竟 $b>0$,还有希望。 |
| 循环四 | $b$ 的最后一位是1,这说明 $\cdot a^8$ 存在。ans ∗= base。由于b再右移一位就是0了,循环结束。 |
总的来说,如果 $b$ 在二进制上的某一位是 $1$,我们就把答案乘上对应的 $a^{2^n}$。
代码
1//求a的b次方
2int quickPower(int a, int b) {
3 int ans = 1, base = a; // ans为答案,base为a^(2^n)
4 while(b > 0) {
5 if(b & 1) {
6 // b&1表示b在二进制下最后一位是不是1,
7 // 如果是把ans乘上对应的a^(2^n)
8 ans *= base;
9 }
10 // base自乘,由a^(2^n)变成a^(2^(n+1))
11 base *= base;
12 // 位运算,b右移一位,10010变成1001。
13 // 现在b在二进制下最后一位是刚刚的倒数第二位。
14 b >>= 1;
15 }
16 return ans;
17}
分治法
分治法可以将较大规模的问题分解成若干个与原问题相似的问题,求解后合并到原问题,从而优化复杂度。
- 确定问题模型
- 确定拆分(合并)性质
- 确定分治终点的解法
二分法
二分查找
1int BinarySearch(vector<int> &v, int target) {
2 int left = 0, right = v.size() - 1;
3 while(left <= right) {
4 int mid = (left + right) / 2;
5 if(v[mid] == target) {
6 return mid;
7 }
8 else if(v[mid] < target) {
9 left = mid + 1;
10 }
11 else {
12 right = mid - 1;
13 }
14 }
15 return -1;
16}
递归写法:
1int BinarySearchRec(vector<int> &a, int left, int right, int target) {
2 int mid = (left + right) / 2;
3 if(left <= right) {
4 if(a[mid] == target) {
5 return mid;
6 }
7 else if(a[mid] < target) {
8 return BinarySearchRec(a, mid + 1, right, target);
9 }
10 else {
11 return BinarySearchRec(a, left, mid - 1, target);
12 }
13 }
14 return -1;
15}
二分答案
参考:博客园-量子流浪猫
二分答案是一种高效(偷懒)的算法技巧,通常用于解决最优化问题,尤其是当问题具有单调性时。它的核心思想是通过二分查找来快速缩小答案的范围,从而找到最优解。
实际上就是不断尝试,只不过使用二分法,时间复杂度低一点。
-
适用场景:
① 最大值最小化或最小值最大化问题。
② 问题具有单调性,即当答案增大或减小时,问题的可行性会呈现单调变化。
③ 直接求解问题较为复杂,但可以通过给定答案快速验证其可行性。 -
步骤
| 步骤 | 操作 |
|---|---|
| 确定搜索范围 | 根据问题的性质,确定答案的可能范围[left, right]。 |
| 计算中间值 | mid = left + (right - left) / 2。 |
| 验证可行性 | 检查mid是否满足条件。如果满足条件,缩小右边界 right = mid,尝试寻找更优的解。如果不满足条件,调整左边界 left = mid + 1。若 left和right的差大于允许的误差值,返回到第二步。 |
| 终止条件 | 当left和right相遇(或两者之差小于允许的误差值)时,输出最优解。 |
- 代码
1int binarySearchAnswer(int left, int right) {
2 while (left < right) {
3 int mid = left + (right - left) / 2;
4 if (check(mid)) { // 检查 mid 是否满足条件
5 right = mid; // 满足条件,尝试更小的值
6 } else {
7 left = mid + 1; // 不满足条件,尝试更大的值
8 }
9 }
10 return left; // 返回最优解
11}
12
13bool check(int mid) {
14 // 根据问题实现具体的检查逻辑
15 // 返回 true 或 false
16}
前缀和与差分
前缀和与差分是算法中常用的技巧,主要用于快速处理与区间操作相关的问题。
参考:博客园-Xbhog
前缀和
- 概念:数组该位置之前的元素之和。
前缀和类似于求一个数列 $a_n$ 的前 $n$ 项和 $S_n$。
- 运算:进行前缀和运算时,下标从1开始。
1// 设数组a[0] = 0
2// 预处理:时间复杂度O(n)
3prefix[1] = a[1]
4prefix[2] = a[1]+a[2] = prefix[1]+a[2]
5prefix[3] = a[1]+a[2]+a[3] = prefix[2] + a[3]
6...
7prefix[n] = a[1]+a[2]+...+a[n] = prefix[n-1]+a[n-1]
为什么下标要从1开始:方便后面的计算,避免下标转换,
a[0]设为零,不影响结果。
- 作用:快速求出元素组中某段区间的和
案例:求数组中 $[l,r]$ 区间的和
如果使用普通循环,需要执行 $l-r$ 次。
1int sum = 0;
2for (int i = l; i <= r; i++) {
3 sum += a[i];
4}
使用前缀和的时间复杂度则降为 $O(n)$。定义两个数组,一个为原始数组a[],一个为前缀和数组prefix[]。
1#include <bits/stdc++.h>
2using namespace std;
3
4// 初始化原数组
5int a[100], prefix[100];
6
7int main() {
8 int l,r,n;
9 cin >> n;
10 for (int i = 1; i <= n; i++) {
11 cin >> a[i]
12 }
13
14 // 前缀和计算:prefix[i] = prefix[i-1]+a[i]
15 for (int i = 1; i <= n; i++) {
16 prefix[i] = prefix[i-1] + a[i];
17 }
18
19 // 输入区间范围[l,r],prefix[r]-prefix[l-1]的结果就是所求区间的和
20 cin >> l >> r;
21 cout << prefix[r] - prefix[l-1];
22
23 return 0;
24}
差分
- 概念:差分是前缀和的逆运算。
- 作用:
(1)快速对一个数组的某个区间内所有元素进行相同的增量或减量操作。
(2)在需要对数组的多个区间进行批量操作时,差分方法可以显著降低复杂度。
重点:构造差分数组diff[]:
1diff[1] = a[1]
2diff[2] = a[2]-a[1]
3diff[3] = a[3]-a[2]
4...
5diff[n] = a[n]-a[n-1]
diff[]称为a[]的差分。相应地,a[]称为diff[]的前缀和。对差分数组做加减操作,再通过计算差分数组的前缀和,会影响原数组相应范围内的所有元素。
1#include <bits/stdc++.h>
2using namespace std;
3
4int a[100], diff[100];
5
6int main() {
7 int l,r,n;
8 cin >> n;
9 for (int i = 1; i <= n ; i++) {
10 cin >> a[i];
11 }
12
13 // 构造差分数组
14 for (int i = 1; i <= n ; i++) {
15 diff[i] = a[i]-a[i-1];
16 }
17
18 cin >> l >> r; // 定义要更改的区间
19 diff[l] += c; // 实现区间[l,n]的所有元素+c
20 diff[r+1] -= c; // 实现区间[r+1,n]的所有元素-c
21
22 // 将差分数组转换成原数组,也就是求差分数组的前缀和。
23 for (int i = 1; i <= n ; i++) {
24 // 类比prefix[i]=prefix[i-1]+a[i]
25 a[i] = a[i-1]+diff[i];
26 }
27
28 return 0;
29}
因为a[]数组是diff[]数组的前缀和,diff[]是a[]的差分,所以在diff[]的某个区间上+c会影响的a区间上的结果
KMP算法
KMP算法是一个经典的字符串匹配算法,解决了朴素字符串匹配算法中因回溯次数过多而造成的时间复杂度过高的问题。
基本思路
在匹配字符串时,当发现某一个字符不匹配的时候,由于已经知道之前遍历过的字符,尽可能多地利用这些信息来避免指针回退的步骤。
这样主串的指针就会永远向前方移动,算法就可以改进为线性时间复杂度了。
步骤
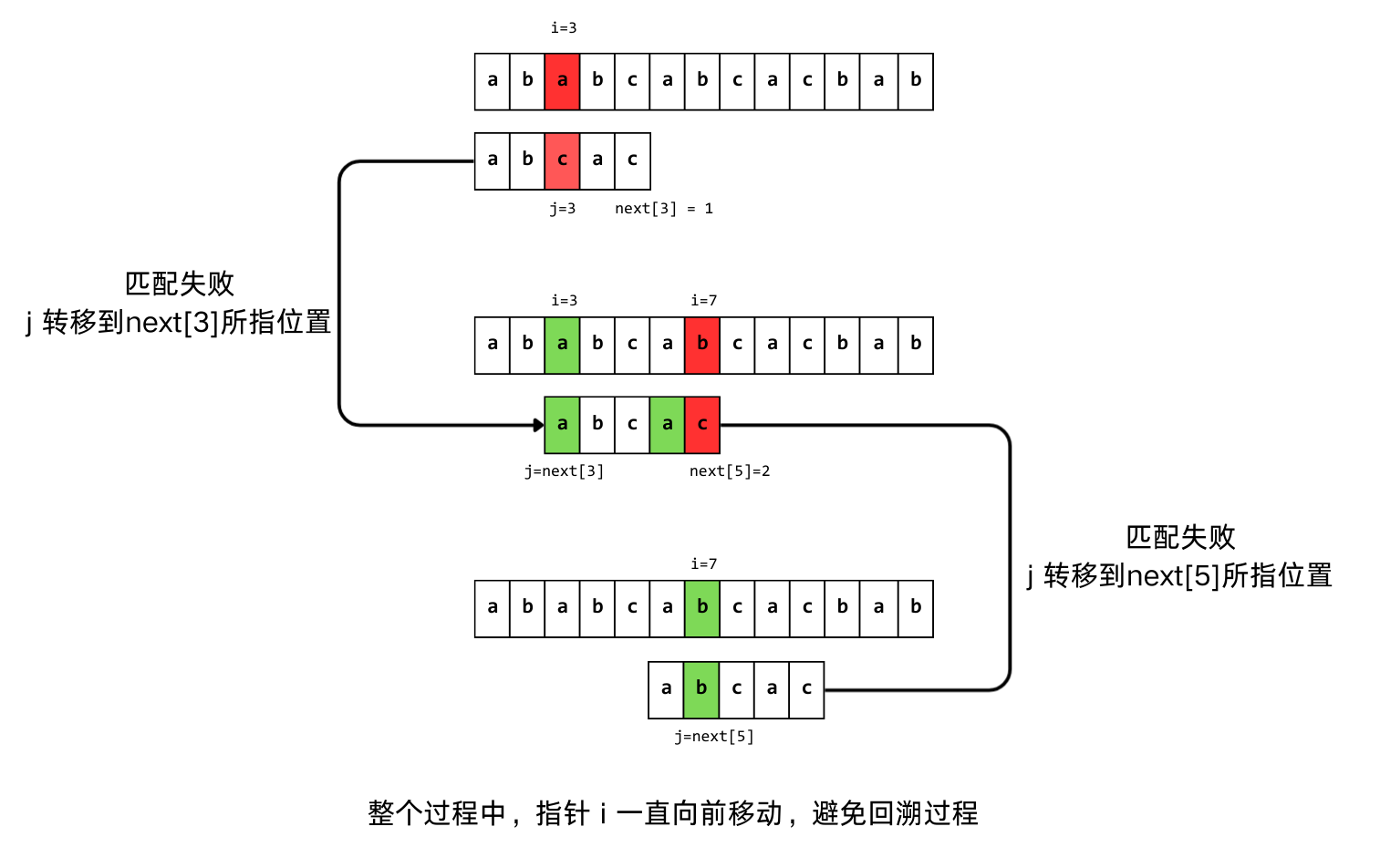
当匹配失败时,模式串指针j要移动的下一个位置k应满足以下性质:模式串最前面的k-1个字符和j之前的最后k-1个字符一样。
我们把匹配失败时模式串指针j要移动的下一个位置k存储到next[]数组中。
这样,当匹配失败时,程序直接读取next[]数组中的值并赋值给指针j,重复匹配操作。
这样可以得出next[]数组的定义:
KMP算法的
next[]数组有多种定义方式,这里采用的是严蔚敏《数据结构(C语言版)》的方法。
代码
1// KMP算法主体
2int KMP(string S, string T, int pos) {
3 i = pos; j = 1;
4 while (i <= S[0] && j <= T[0]) {
5 if (j == 0 || S[i] == T[i]) {
6 // 匹配成功时,继续比较后续字符
7 i++; j++;
8 }
9 else {
10 // 匹配失败时,模式串向右移动
11 j = next[j];
12 }
13 }
14 if (j > T[0]) {
15 // 匹配成功
16 return i-T[0];
17 }
18 return 0;
19}
20
21// 求next数组
22void get_next(String T, int next[]) {
23 i = 1; next[1] = 0; j = 0;
24 while (i < T[0]) {
25 if (j == 0 || T[i] == T[j]) {
26 i++; j++; next[i] = j;
27 }
28 else {
29 j = next[j];
30 }
31 }
32}
搜索
图的存储
邻接表:vector建表。将每个点X的邻接点存入数组g[X]中。
1vector<int> g[N]
广度优先搜索
1void Graph_Traverse (AdjGraph G) {
2 int *visited = new int [MaxVexNum];
3 for (int i = 0; i < G.n; i++ ) {
4 // 访问数组 visited 初始化
5 visited [i] = 0;
6 }
7 for (int i = 0; i < G.n; i++ ) {
8 if (!visited[i]) {
9 // 从顶点 i 出发开始搜索
10 BFS(G, i, visited);
11 }
12 }
13 delete[] visited; // 释放 visited
14}