基本概念
| 基本概念 | 内容 |
|---|---|
| 查找表 | 由同一类型数据结构组成的集合 |
| 静态查找表 | 仅作查询或检索操作的查找表 |
| 动态查找表 | 在查找表插入中查找不存在的数据元素,或者从查找表中删除已存在的某个数据元素 |
| 关键字 | 数据元素中某个数据项的值,可以标识一个数据元素 |
| 主关键字 | 可以唯一标识一个数据元素的关键字 |
| 查找 | 根据给定的某个值,在查找表中确定一个关键字等于定值的数据元素 |
查找方法的评价指标:
- 查找速度
- 占用存储空间
- 算法本身复杂程度
平均查找长度ASL:
为确定记录在表中的位置,需和给定值进行比较的关键字的个数的期望值称作查找算法的ASL。
对含有 $n$ 个记录的表,
$$ASL=\sum_{i=𝟏}^{n} p_i c_i$$其中:$p_i$ 为查找表中第 $i$ 个元素的概率,$\displaystyle \sum_{i=𝟏}^{n} p_i =1$,$c_i$ 为查找表中第 $i$ 个元素所需比较次数。
静态查找表
顺序表的查找
1int Search_Seq(SSTable ST, KeyType key) {
2 // 在顺序表ST中顺序查找其关键字等于key的数据元素。
3 // 若找到,则函数值为该元素在表中的位置,否则为0。
4 int i = 0;
5 ST.elem[0].key = key; // 设置哨兵
6 // 从后往前找
7 for(i = ST.length; ST.elem[i].key != key; --i) ;
8 return i; // 找不到时,i为0
9}
查找性能分析:
- 在等概率查找的情况下,$\displaystyle p_i = \frac{1}{n}$,顺序表查找成功时的平均查找长度为:$$ASL = \frac{1}{n} \sum_{i=1}^{n} (n-i+1) = \frac{n+1}{n} $$
- 如果考虑上查找不成功的情况,且查找成功与不成功的可能性相同,对每个记录的查找概率也相等,即 $\displaystyle p_i = \frac{1}{2n}$,此时顺序查找的平均查找长度为 $$ ASL = \frac{1}{2n} \sum_{i=1}^{n} (n-i+1) + \frac{1}{2}(n+1) = \frac{3}{4}(n+1) $$
- 在不等概率查找的情况下, $ASL$ 在 $p_n \geqslant p_{n-1} \geqslant \cdots \geqslant p_1$ 时取极小值。将表中记录按查找概率由小到大重新排列,可以提高查找效率。
- 若查找概率无法事先测定,则查找过程采取的改进办法是:在每次查找之后,将刚刚查找到的记录直接移至表尾的位置上。
有序表的查找
折半查找
设表长为 $n$,low、high和mid分别指向待查元素所在区间的下界、上界和中点,key为给定值。
初始时,令low = 1,high = n,mid = (low+high)/2,让key与mid指向的记录比较:
- 若
key == r[mid].key,查找成功; - 若
key < r[mid].key,则high = mid – 1; - 若
key > r[mid].key,则low = mid + 1; - 重复步骤3和4,直至
low > high时,查找失败。
1int Search_Bin(SSTable ST, KeyType key) {
2 // 置区间初值
3 int low = 1;
4 int high = ST.length;
5 while(low <= high) {
6 int mid = (low + high) / 2;
7 if(key == ST.elem[mid].key) {
8 return mid; // 找到待查元素
9 }
10 else if(key < ST.elem[mid].key) {
11 high = mid - 1; // 继续在前半区间进行查找
12 }
13 else {
14 low = mid + 1; // 继续在后半区间进行查找
15 }
16 }
17 return 0; // 顺序表中不存在待查元素
18}
折半查找的性能分析:折半查找法在查找过程中进行的比较次数最多不超过 $\lfloor \log n \rfloor+1$
分块查找
索引顺序查找,又称分块查找
| 内容 | |
|---|---|
| 查找过程 | 将表分成几块,块内无序,块间有序;先确定待查记录所在块,再在块内查找 |
| 适用条件 | 分块有序表 |
| 算法实现 | 用数组存放待查记录,每个数据元素至少含有关键字域; 建立索引表,每个索引表结点含有最大关键字域和指向本块第一个结点的指针 |
| 性能分析 | $$ASL = L_B + L_W$$ 其中 $L_B$ 为查找索引表确定所在块的平均查找长度,$L_W$ 为在块中查找元素的平均查找长度 |
动态查找表
特点:表结构本身是在查找过程中动态生成。若表中存在其关键字等于给定值key的数据元素,表明查找成功;否则插入关键字等于key的数据元素。
二叉排序树
| 定义 | |
|---|---|
| 情况1 | 一棵空树 |
| 情况2 | 若它的左子树不空,则左子树上所有结点的值均小于根结点的值 |
| 若它的右子树不空,则右子树上所有结点的值均大于根结点的值 | |
| 它的左、右子树也都分别是二叉排序树 |
1// 二叉排序树的定义
2typedef struct BiTNode {
3 TElemType data;
4 struct BiTNode *lchild, *rchild; // 左右指针
5 } BiTNode, *BiTree;
查找算法
| 情况 | 结论 |
|---|---|
| 若二叉排序树为空 | 查找不成功 |
| 若二叉排序树非空 | 若给定值等于根结点的关键字,则查找成功 若给定值小于根结点的关键字,则继续在左子树上进行查找 若给定值大于根结点的关键字,则继续在右子树上进行查找 |
算法实现:
1BiTree SearchBST(BiTree T, KeyType key) {
2 // 查找不成功,返回空
3 if (!T) {
4 return NULL;
5 }
6 // 查找成功,返回树根
7 else if( key == T->data.key ) {
8 return T;
9 }
10 else if( key < T->data.key ) {
11 // 在左子树中继续查找
12 return SearchBST(T->lchild, key);
13 }
14 else {
15 // 在右子树中继续查找
16 return SearchBST(T->rchild, key);
17 }
18}
插入算法
| 要求 | |
|---|---|
| 开始条件 | 当查找不成功时,才进行“插入”操作 |
| 算法要求 | 在完成插入结点的操作后,仍要保持二叉排序树特性 |
| 算法过程 | 若二叉排序树为空树,则新插入的结点为新的根结点; 否则,新插入的结点必为新的叶结点,其插入位置由查找过程得到 |
1// 更新搜索算法:f指向T的双亲,p记录查找位置
2bool SearchBST(BiTree T, KeyType key, BiTree f, BiTree &p) {
3 // 查找不成功
4 if(!T) {
5 p = f;
6 return false;
7 }
8 // 查找成功
9 else if(key == T->data.key) {
10 p = T;
11 return true;
12 }
13 else if(key < T->data.key) {
14 return SearchBST(T->lchild, key, T, p);
15 }
16 else {
17 return SearchBST(T->rchild, key, T, p);
18 }
19}
20
21// 插入算法
22bool InsertBST(BiTree &T, ElemType e) {
23 if (!SearchBST (T, e.key, NULL, p)) {
24 BiNode *s = new BiTNode; // 为新结点分配空间
25 s->data = e;
26 s->lchild = s->rchild = NULL;
27 if(!p) {
28 T = s; // 插入 s 为新的根结点
29 }
30 else if(e.key < p->data.key) {
31 p->lchild = s; // 插入 *s 为 *p 的左孩子
32 }
33 else {
34 p->rchild = s; // 插入 *s 为 *p 的右孩子
35 }
36 return true;
37 }
38 else {
39 return false;
40 }
41}
删除算法
| 要求 | |
|---|---|
| 开始条件 | 当查找成功时,才进行“删除”操作 |
| 算法要求 | 在完成删除结点的操作后,仍要保持二叉排序树特性 |
| 具体情况 | 被删除的结点是叶子结点:其双亲结点中相应指针域的值改为空 被删除的结点只有左子树或者只有右子树:其双亲结点的相应指针域的值指向被删除结点的左子树或右子树 被删除的结点既有左子树,也有右子树:以其前驱替代之,然后再删除该前驱结点 |
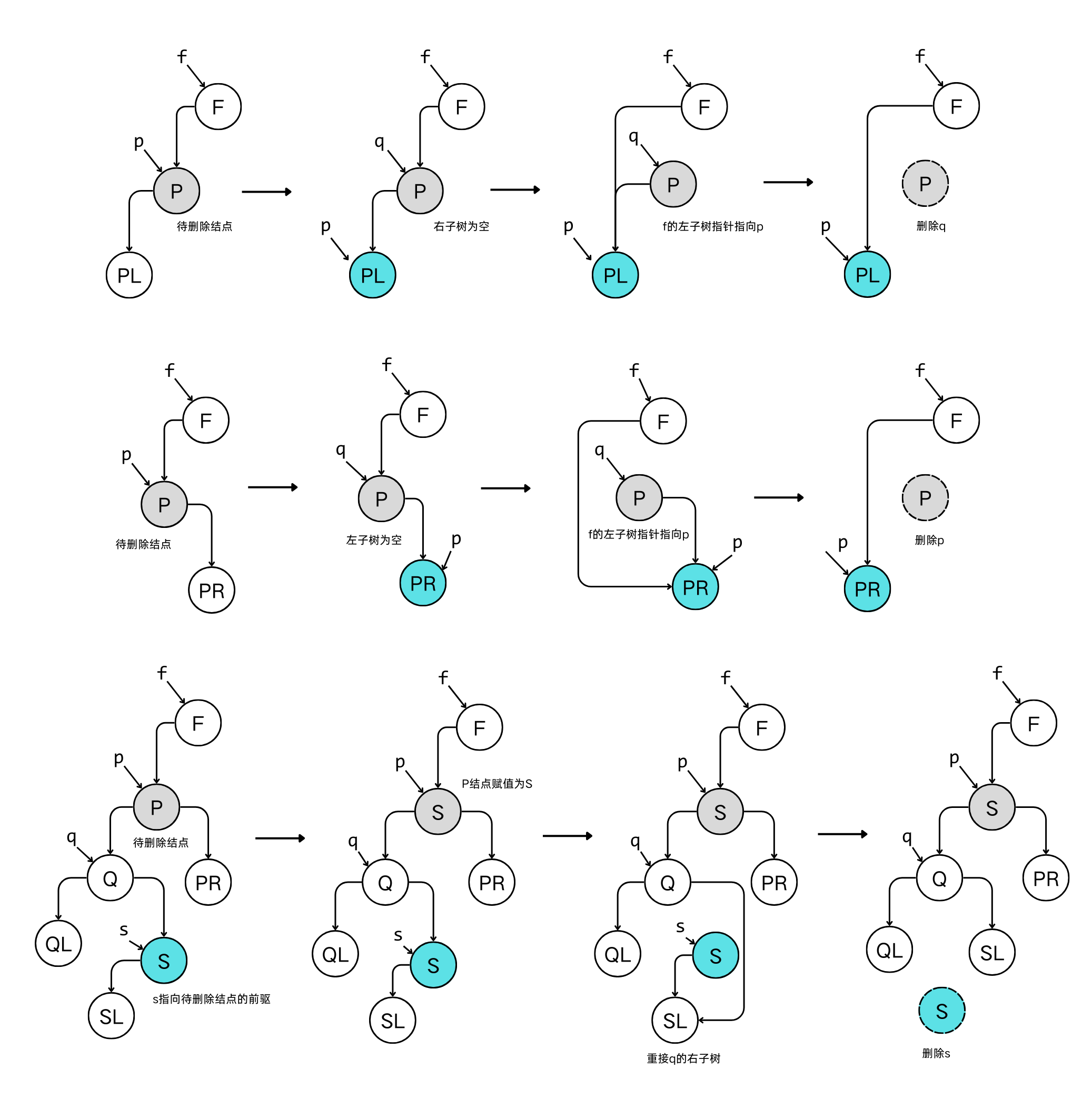
1/* ----- 删除主函数 ----- */
2bool DeleteBST(BiTree &T, KeyType key, BiTree &f) {
3 if (!T) {
4 return false; // 不存在关键字等于 key 的数据元素
5 }
6 else {
7 // 找到关键字等于 key 的数据元素
8 if(key == T->data.key) {
9 Delete(T, f);
10 return true;
11 }
12 // 继续在左子树中查找
13 else if(key < T->data.key) {
14 return DeleteBST(T->lchild, key, T);
15 }
16 // 继续在右子树中查找
17 else {
18 return DeleteBST(T->rchild, key, T);
19 }
20 }
21}
22
23/* ----- 删除操作过程 ----- */
24void Delete(BiTree &p, BiTree f) {
25 BiTree *q = (BiTree*)malloc(sizeof(BiTree));
26 // 从二叉排序树中删除结点 p,并重接它的左子树或右子树
27
28 // 右子树为空树,则只需重接它的左子树
29 if(!p->rchild) {
30 q = p;
31 p = p->lchild;
32 if(f->lchild == q) {
33 f->lchild = p;
34 }
35 else if(f->rchild == q) {
36 f->rchild = p;
37 }
38 delete(q);
39 }
40 // 左子树为空树,只需重接它的右子树
41 else if(!p->lchild) {
42 q = p;
43 p = p->rchild;
44 if (f->lchild == q) {
45 f->lchild = p;
46 }
47 else if(f->rchild == q) {
48 f->rchild = p;
49 }
50 delete(q);
51 }
52 // 左右子树均不空
53 else {
54 q = p;
55 s = p->lchild;
56 while (s->rchild) {
57 q = s;
58 s = s->rchild;
59 } // s 指向被删结点的前驱
60 p->data = s->data;
61 // 重接*q的左子树
62 if(q != p ) {
63 q->rchild = s->lchild;
64 }
65 else {
66 q->lchild = s->lchild;
67 }
68 delete(s);
69 }
70}
平衡二叉树
平衡二叉树(AVL树)也是二叉排序树。
特点:树中每个结点的左、右子树深度之差(平衡因子 BF)的绝对值不大于1,即 $\left|h_L - h_R\right| \leqslant 1$
构造
在插入过程中,若失去平衡,则需要采用平衡旋转技术:
| 类别 | 特点 |
|---|---|
| LL型 | 向右旋转,BF(B)由1变为0,BF(A)由2变为0 |
| RR型 | 向左旋转,BF(B)由-1变为0,BF(A)由-2变为0 |
| LR型 | 双向旋转,BF(A)由2变为-1,BF(B)由-1变为0,BF(C)由1变为0 |
| RL型 | 双向旋转,BF(A)由-2变为0,BF(B)由1变为-1,BF(C)由1变为0 |
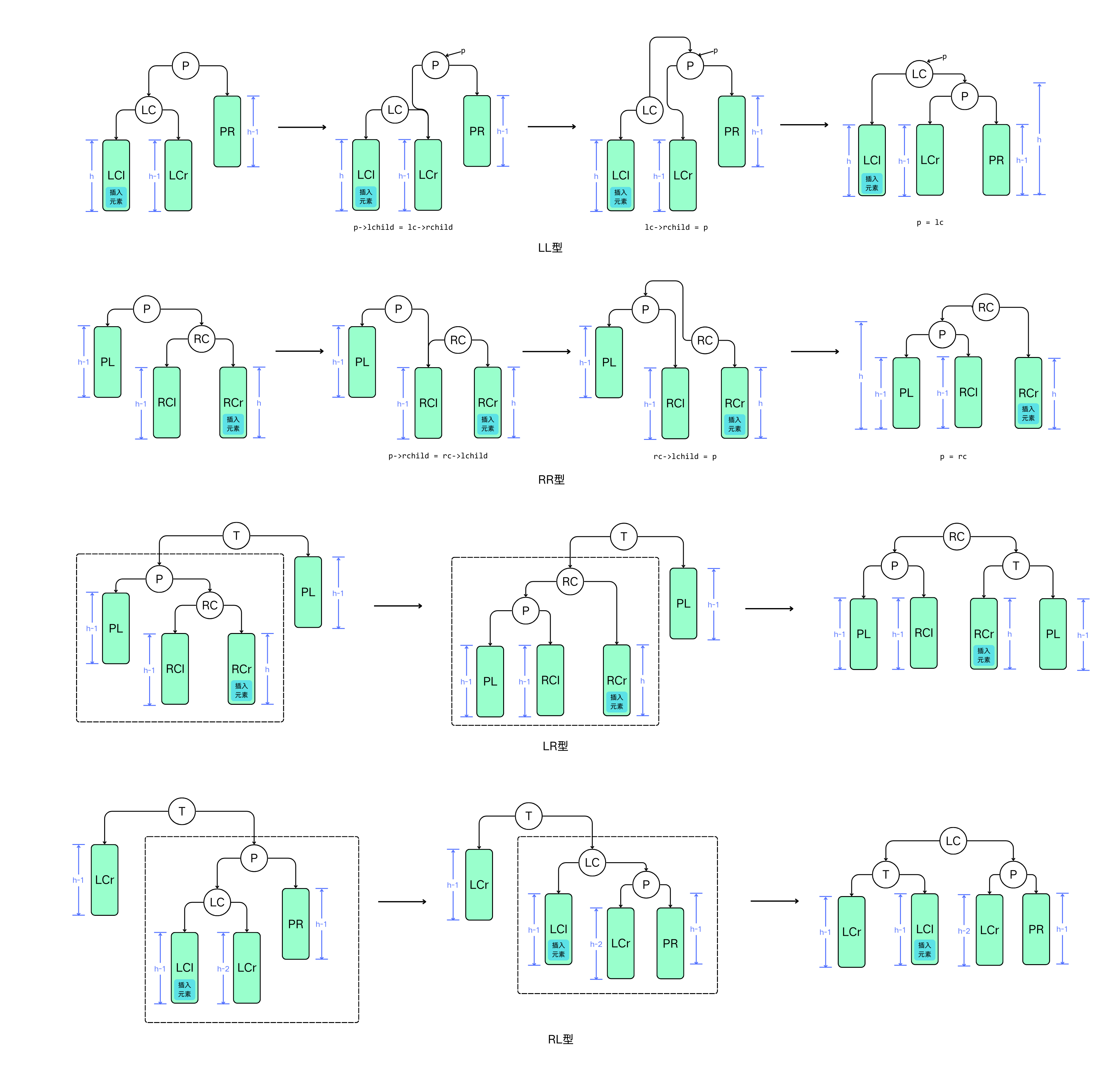
1// 右旋算法
2void R_Rotate(BSTree &p){
3 lc = p->lchild;
4 p->lchild = lc->rchild;
5 lc->rchild = p;
6 p = lc;
7}
8
9// 左旋算法
10void L_Rotate(BSTree &p){
11 rc = p->rchild;
12 p->rchild = rc->lchild;
13 rc->lchild = p;
14 p = rc;
15}
16
17// 左平衡算法
18#define LH 1 // 左高
19#define EH 0 // 等高
20#define RH -1 // 右高
21
22void LeftBalance(BSTree &T) { // T对应图中的树根A
23 lc = T->lchild; // lc对应图中的树根B
24 switch(lc->bf) { // 看T的左子(B),只能是LL或LR型
25 // 左左->右旋(LL型)
26 case LH:
27 T->bf = lc->bf = EH;
28 R_Rotate(T);
29 break;
30 // LR型,先左旋后右旋
31 case RH:
32 rd = lc->rchild; // 结点C
33 switch(rd->bf) { // 修改BF值
34 case LH:
35 T->bf = RH;
36 lc->bf = EH;
37 break;
38 case EH:
39 T->bf = lc->bf = EH;
40 break;
41 case RH:
42 T->bf = EH;
43 lc->bf = LH;
44 break;
45 }
46 rd->bf = EH;
47 L_Rotate(T->lchild);
48 R_Rotate(T);
49 }
50}
呜呜呜,这部分实在是太难了,恳请高人指点……
B-树
B-树是一种平衡的多路查找树
| 定义 | |
|---|---|
| 情况1 | 一棵空树 |
| 情况2 | 树中每个结点至多有 $m$ 棵子树 |
| 若根结点不是叶子结点,则至少有两棵子树 | |
| 除根结点之外的所有非终端结点至少有 $\lfloor m/2 \rfloor$ 棵子树 | |
| 所有的非终端结点中包含下列信息数据 $(n, A_0, K_1, A_1, K_2, A_2, \cdots, K_n, A_n)$ | |
| 所有的叶子结点都出现在同一层次上,并且不带信息(空指针) |
$K_i$ $(i = 1, 2, \cdots, n)$ 为关键字,且 $K_i < K_{i+1}$ $(i = 1, 2, \cdots, n-1)$。
$A_i$ $(i = 0, 1, …, n)$ 为指向子树根结点的指针,且指针 $A_{i-1}$ 所指子树中所有结点的关键字均小于 $K_i$ $(i = 1, 2, \cdots, n)$,$A_n$ 所指子树中所有结点的关键字均大于 $K_n$,$n$ $(\lceil m/2 \rceil - 1 \leqslant n \leqslant m-1)$ 为关键字的个数(或 $n+1$ 为子树个数)。
一棵 $m$ 阶B-树每个结点最多有 $m$ 棵子树,$m–1$ 个关键字,最少有 $\lceil m/2 \rceil$ 棵子树, $\lceil m/2 \rceil –1$ 个关键字。
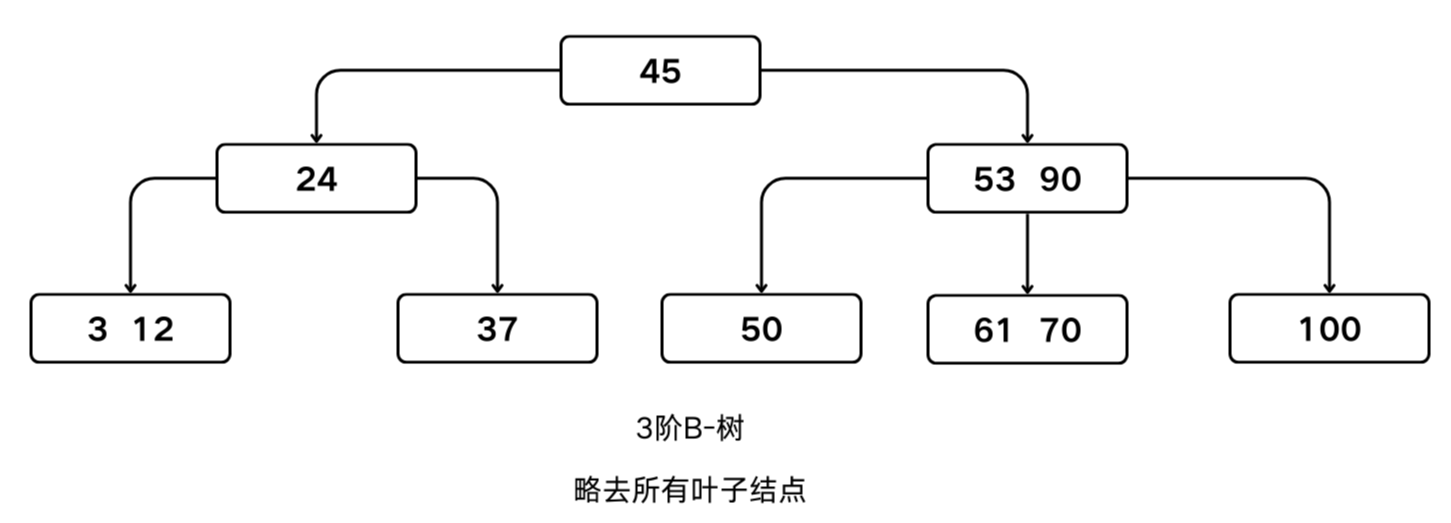
B-树
插入
每次插入时,尽可能插入到最后一层非叶结点上。
- $\lceil m/2 \rceil – 1 \leqslant$ 结点中的关键字个数 $\leqslant m–1$;
- 每次插入一个关键字不是在树中添加一个叶子结点,而是在查找的过程中找到叶子结点所在层的上一层;
- 在某个结点中添加一个关键字,若结点的关键字个数不超过 $m–1$,则插入完成;
- 否则产生结点的“分裂”。
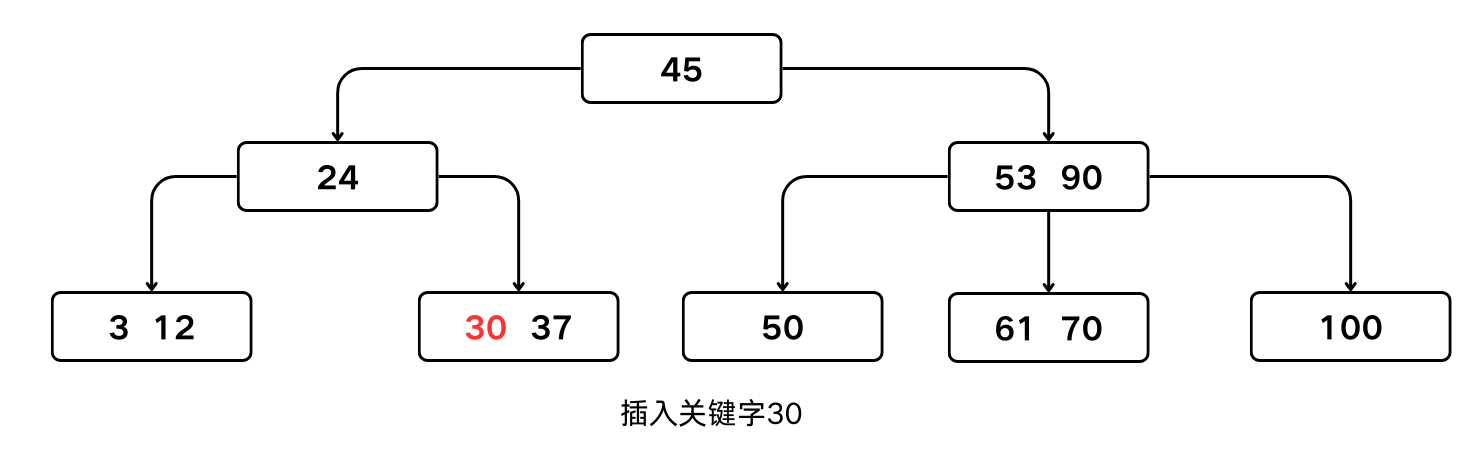
B-树的普通插入
一般情况下,假设结点
$$m,A_0,(K_1, A_1),(K_2, A_2),\cdots,(K_m, A_m)$$p中已经有 $m-1$ 个关键字,当插入一个关键字之后,结点中含有的信息为此时可将结点拆分成
p和p'两个结点,
结点 信息 p$\lceil m/2 \rceil -1,A_0,(K_1, A_1),\cdots,(K_{\lceil m/2 \rceil -1}, A_{\lceil m/2 \rceil -1})$ p'$m-\lceil m/2 \rceil,A_{\lceil m/2 \rceil},(K_{\lceil m/2 \rceil +1}, A_{\lceil m/2 \rceil +1}),\cdots,(K_m, A_m)$ 而关键字 $K_{\lceil m/2 \rceil}$ 和指针
*p'一起插入到p的双亲结点中。
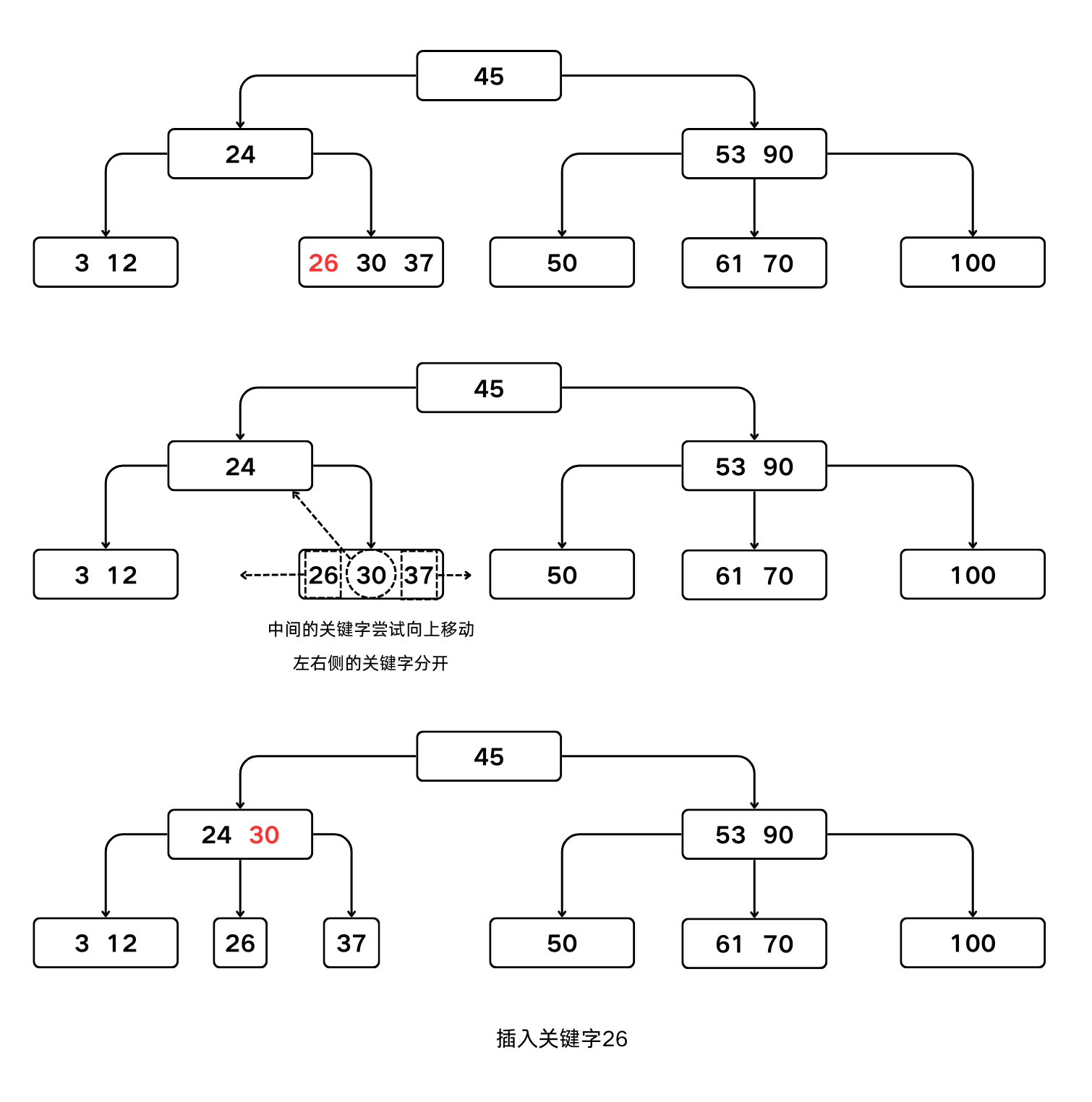
B-树的特殊插入
删除
| 删除结点类型 | 操作 |
|---|---|
| 非终端结点 | 设关键字为 $K_i$,则可以用 $A_i$ 指向子树的最小关键字或 $A_{i-1}$ 指向子树的最大关键字替换 $K_i$,再删去该关键字即可,而该关键字必定在终端结点。 |
| 终端结点 | 若删除后仍满足B-树定义,则删除结束;否则要进行合并结点的操作。 |
删除操作:
- 若被删关键字所在结点中的关键字数目不小于 $\lceil m/2 \rceil$,则只需从该结点中删去该结点中删去该关键字 $K_i$ 和相应指针 $A_i$,树的其他部分不变。
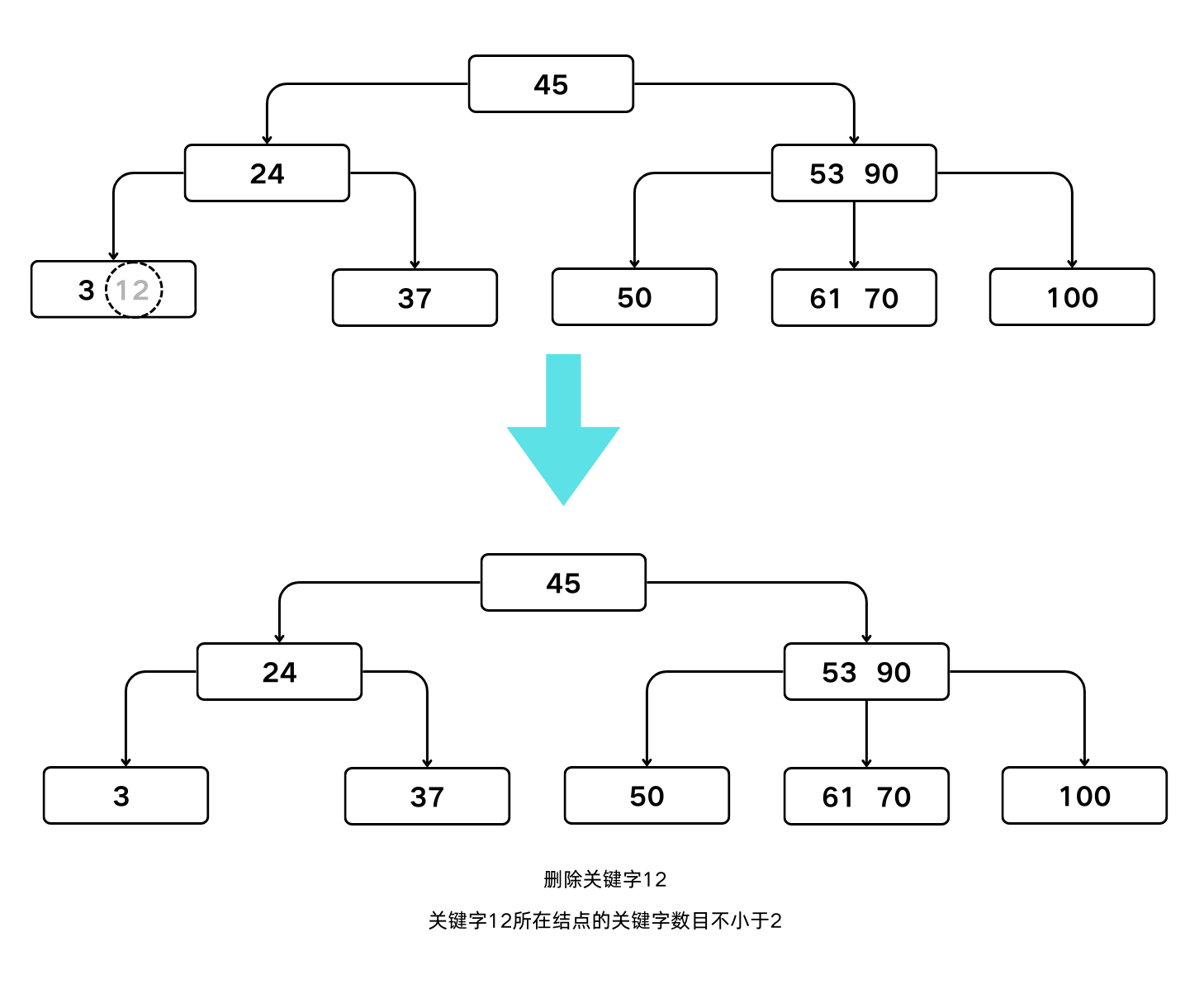
B-树的第1种删除
- 若被删关键字所在结点的关键字数目等于 $\lceil m/2 \rceil -1$,而与该结点相邻的右兄弟(左兄弟)结点中的关键字数目大于 $\lceil m/2 \rceil-1$,则需将其兄弟结点中的最小(最大)的关键字上移到双亲结点中,而将双亲结点中小于(大于)且紧靠该上移关键字的关键字下移到被删关键字所在的结点中。
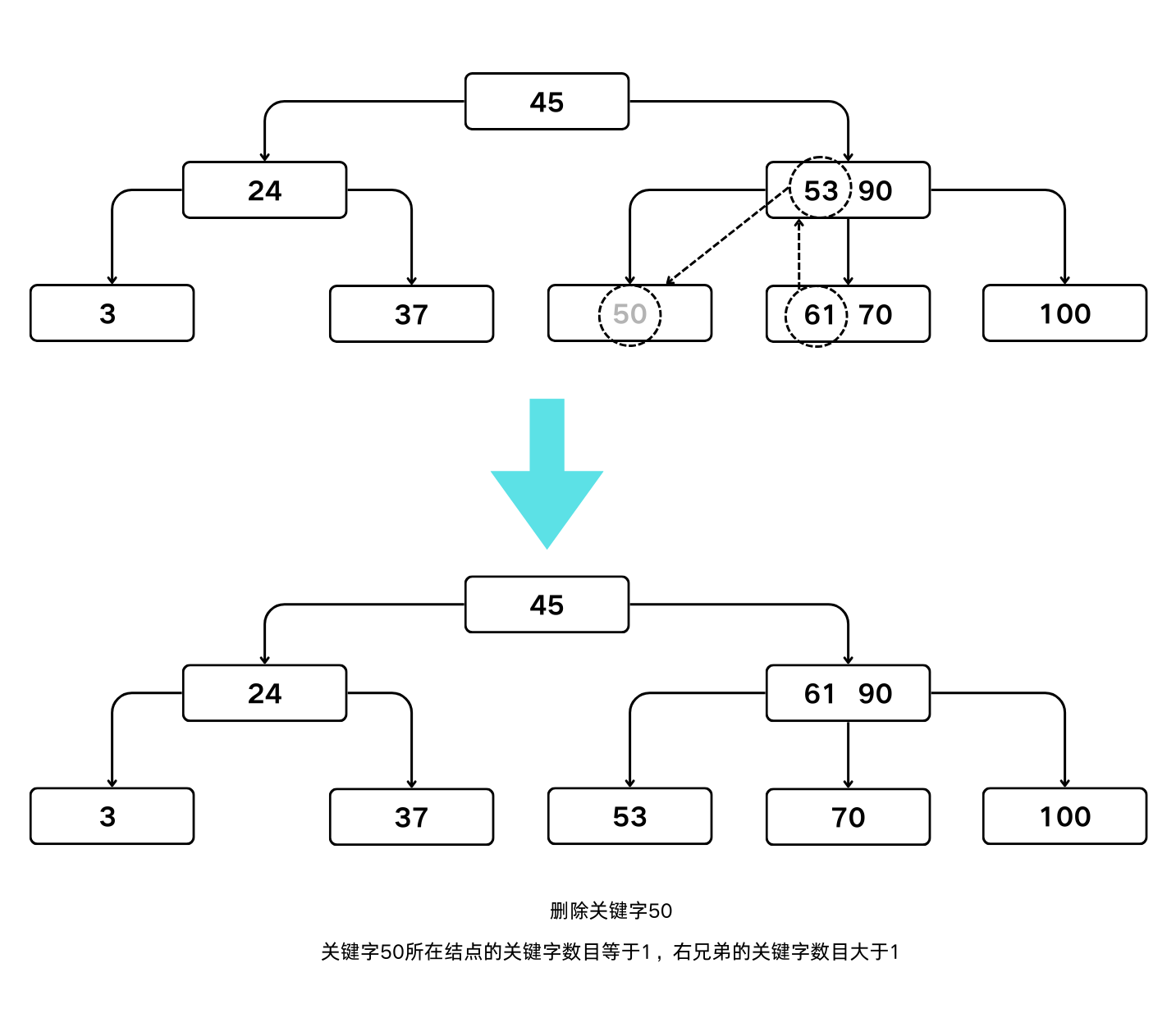
B-树的第2种删除
- 若被删关键字所在结点和其相邻的兄弟结点中的关键字数目均等于 $\lceil m/2 \rceil -1$,则在删去关键字后,它所在结点中剩余的关键字和指针加上双亲中的关键字 $K_i$ 一起,合并到 $A_i$ 所指的兄弟结点中。
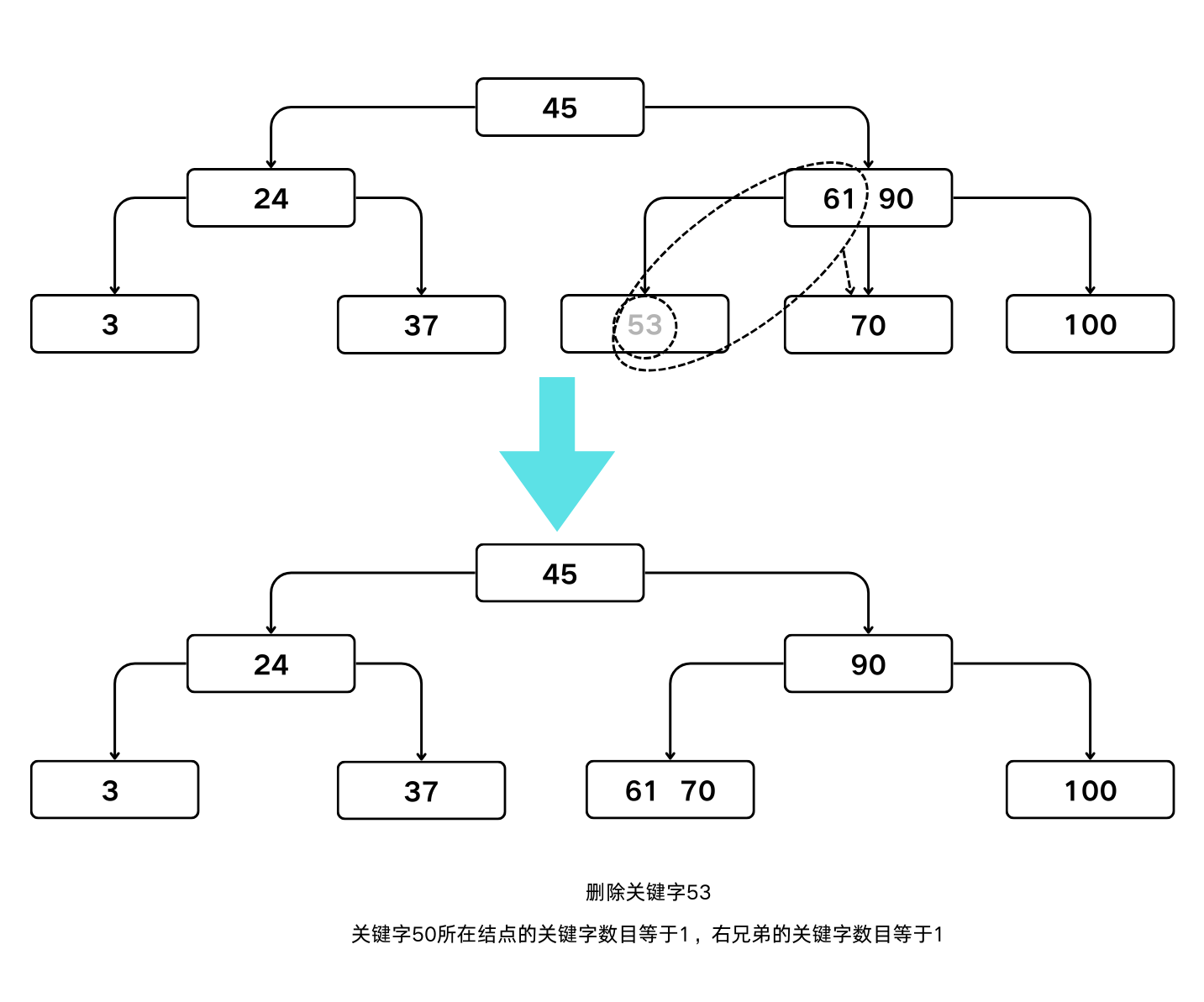
B-树的第3种删除
- 若删除后使双亲结点中的关键字数目小于 $\lceil m/2 \rceil –1$,则依此类推层层向上合并。
哈希表
在数据元素的存储地址和它的关键字之间建立一个确定的对应关系,这样,不经过比较,一次存取就能得到所查元素。
基本概念
| 概念 | 内容 |
|---|---|
| 哈希查找 | 利用哈希函数进行查找的过程 |
| 哈希函数 | 在数据元素的关键字与存储地址之间建立的一种对应关系。哈希函数是一种映象,是从关键字空间到存储地址空间的一种映象 |
| 哈希表 | 根据设定的哈希函数 $H(key)$ 和所选中的处理冲突的方法,将一组关键字映象到一个有限的、地址连续的地址集(区间)上,并以关键字在地址集中的“象”作为相应记录在表中的存储位置,如此构造所得的查找表称之为“哈希表” |
哈希函数只是一种映象,所以哈希函数的设定很灵活,只要使任何关键字的哈希函数值都落在表长允许的范围之内即可。
哈希函数的构造
| 构造方法 | 适用范围 | 操作 |
|---|---|---|
| 直接定址法 | 地址集合的大小 = 关键字集合的大小 | 哈希函数为关键字的线性函数 $H(key) = a \times key + b$ 其中a和b为常数 |
| 数字分析法 | 能预先估计出全体关键字的每一位上各种数字出现的频度 | 从关键字中提取分布均匀的若干位或其组合作为地址 |
| 平方取中法 | 关键字中的每一位都有某些数字重复出现频度很高 | 关键字的平方值的中间几位作为存储地址 |
| 折叠法 | 关键字的数字位数特别多 | 将关键字分割成若干部分,然后取叠加和为哈希地址 |
| 除留余数法 | $H(key) = key MOD p$ $( p \leqslant m )$ 其中,$m$ 为表长,$p$ 为不大于 $m$ 的质数或是不含 $20$ 以下质因子的合数 | |
| 随机数法 | 关键字的长度不等 | $H(key) = \mathrm{Random}(key)$ |
处理冲突
冲突:$key_1 \ne key_2$,但 $H(key_1) = H(key_2)$ 的现象
是否可以完全避免哈希冲突?
一般来说,只能尽量减少冲突而不能完全避免冲突;
这是因为通常关键字集合比较大,其元素包括所有可能的关键字,而地址集合的元素仅为哈希表中的地址值。
构造原则:在定义哈希表时既要定义好哈希函数又要给出处理冲突的方法。
“处理冲突”:为产生冲突的地址寻找下一个哈希地址。
| 处理冲突的方法 | 具体操作 |
|---|---|
| 开放定址法 | 为产生冲突的地址H(key)求得一个地址序列: H1, H2, …, Hs $(1 \leqslant s \leqslant m–1)$ |
| 再哈希法 | 构造若干个哈希函数,当发生冲突时,计算下一个哈希地址,直到冲突不再发生 |
| 链地址法 | 将所有哈希地址相同的记录都链接在同一链表中 |
| 建立公共溢出区 | 所有关键字冲突的记录都填入溢出表 |
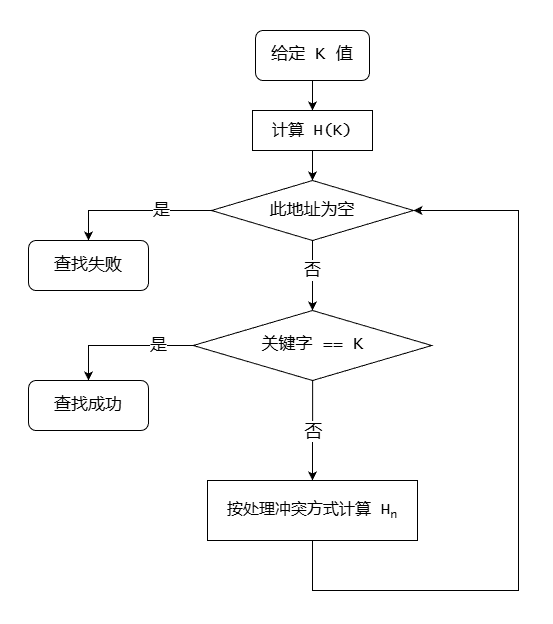
哈希表的查找
对于给定值K,计算哈希地址 i = H(K):
- 若
r[i] == NULL,则查找失败; - 若
r[i].key == K,则查找成功; - 否则求下一地址
Hi直至下面两种情况之一为止:r[Hi] == NULL(查找失败);r[Hi].key == K(查找成功)