树是由 $n$ $(n>0)$ 个结点的有限集合。如果 $n=0$,称为空树;如果 $n>0$,则
- 有且仅有一个根结点,它没有直接前驱。
- 当 $n>1$,除根结点以外的其他结点划分为 $m$ $(m>0)$ 个互不相交的有限集 $T_1, T_2, \cdots , T_m$,其中每个集合本身又是一棵树,并且称为根的子树。
由树的性质可知,树的结构具有递归性。
树的基本概念
| 基本概念 | 含义 |
|---|---|
| 结点 | 一个数据元素及其指向结点的分支 |
| 度 | 结点拥有的子树个数 |
| 叶结点 | 度为 $0$ 的节点 |
| 子女 | 结点子树的根 |
| 兄弟 | 同一个结点的子女 |
| 祖先 | 根结点到该结点路径上的所有结点 |
| 子孙 | 某结点为根结点的子树上的任意结点 |
| 层 | 以根结点为第一层,根结点的子女为第二层,以此类推 |
| 树的深度 | 树中结点的最大层数 |
| 有序树 | 树中结点的子树从左向右有序 |
| 森林 | $m$ $(m \geqslant 2)$ 棵互不相交的树 |
二叉树
二叉树是结点的一个有限集合,该集合或者为空,或者是由一个根结点加上互不相交的左右子树。
二叉树具有以下性质:
- 在二叉树的第 $i$ $(i \geqslant 1)$ 层上至多有 $2^{i-1}$ 个结点。
- 深度为 $k$ $(k \geqslant 1)$ 的二叉树至多有 $2^{k-1}$ 个结点。
- 对任意一个二叉树 $T$,如果其叶结点数为 $n_0$,度为 $2$ 的结点数为 $n_2$,则 $n_0 = n_2 + 1$。
- 拥有 $n$ $(n \geqslant 0)$ 个结点的完全二叉树的深度为 $\left[ \log_{2}(n)\right] + 1$
二叉树的存储
- 顺序存储
- 链式存储
1/* ----- 二叉树的链式表示 ----- */
2typedef char TreeData;
3
4typedef struct node {
5 TreeData data;
6 struct node *leftChild; *rightChild;
7};
8
9typedef BinTreeNode *BinTree;
二叉树的操作
遍历
按某种次序访问树中所有结点,并且每个结点仅访问一次的操作。
1// 访问结点
2void visit(BinTreeNode *T) {
3 if (T != NULL) {
4 printf(T->data);
5 }
6}
遍历分为广度优先遍历和深度优先遍历两种。
| 遍历的方式 | 性质 | 具体内容 |
|---|---|---|
| 层序遍历 | 广度优先 | 逐层从左至右,从上到下访问 |
| 先序遍历 | 深度优先 | 先访问根结点,再访问左子树,最后访问右子树 |
| 中序遍历 | 深度优先 | 先访问左子树,再访问根结点,最后访问右子树 |
| 后序遍历 | 深度优先 | 先访问左子树,再访问右子树,最后访问根结点 |
1// 先序遍历
2void PreOrder(BinTreeNode *T) {
3 if (T != NULL) {
4 visit(T->data);
5 PreOrder(T->leftChild);
6 PreOrder(T->rightChild);
7 }
8}
9
10// 中序遍历
11void InOrder(BinTreeNode *T) {
12 if (T != NULL) {
13 PreOrder(T->leftChild);
14 visit(T->data);
15 PreOrder(T->rightChild);
16 }
17}
18
19// 后序遍历
20void PostOrder(BinTreeNode *T) {
21 if (T != NULL) {
22 PreOrder(T->leftChild);
23 PreOrder(T->rightChild);
24 visit(T->data);
25 }
26}
获取二叉树的相关信息
二叉树的操作函数基本都是以递归作为执行的核心逻辑。
1// 按前序建立二叉树
2void CreateBiTree(BiTree* &T) {
3 scanf(&ch);
4 if (ch == '@') {
5 T = NULL;
6 }
7 else {
8 T = (BiTree*)malloc(sizeof(BiTree));
9 T->data = ch;
10 CreateBiTree(T->leftChild);
11 CreateBiTree(T->rightChild);
12 }
13}
14
15// 计算二叉树结点个数
16int cnt = 0;
17void NodeCount(BiTree* &T) {
18 if (T != NULL) {
19 cnt ++;
20 Count(T->leftChild);
21 Count(T->rightChild);
22 }
23}
24
25// 求二叉树叶结点个数
26int LeafCount(BiTree* &T) {
27 if (!T) {
28 return 0;
29 }
30 else if (!T->leftChild && !T->rightChild) {
31 return 1;
32 }
33 else {
34 return LeafCount(T->leftChild) + LeafCount(T->rightChild);
35 }
36}
37
38// 求二叉树高度
39int Height(BiTree* &T) {
40 if (T == NULL) {
41 return 0;
42 }
43 else {
44 int m = Height(T->leftChild);
45 int n = Height(T->rightChild);
46 return (m>n) ? m+1 : n+1;
47 }
48}
二叉树的重构
重构:由二叉树的若干遍历序列,复现二叉树的原本结构。
| 已知遍历 | 结论 |
|---|---|
| 先序 + 中序 | 可重构 |
| 后序 + 中序 | 可重构 |
| 先序 + 后序 | 不可重构 |
1// 重构二叉树
2void BuildTree(BinTreeNode* &T, ElemType PreStart, ElemType PreEnd,
3 ElemType InStart, ElemType InEnd) {
4 // 递归终点
5 if (PreStart > PreEnd || InStart > InEnd) {
6 return;
7 }
8
9 T = new BinTreeNode();
10 // 当前子树的根结点
11 T->data = PreSeq[PreStart];
12 T->leftChild = NULL;
13 T->rightChild = NULL;
14
15 // 寻找中序遍历的根结点位置
16 int root = find(T->data, InSeq, InStart, InEnd);
17 // 计算左子树结点数目
18 int nL = root - InStart;
19
20 // 递归构建左子树
21 BuildTree(T->leftChild, PreStart+1, PreStart+nL, InStart, root-1);
22 // 递归构建右子树
23 BuildTree(T->rightChild, PreStart+nL+1, PreEnd, root+1, InEnd);
24}
线索二叉树
线索二叉树中,除根节点外,每个结点都有自己的前驱和后继。
用二叉链表表示的二叉树中,$n$ 个结点的二叉树有 $n+1$个空链域,可利用这些空链域存储结点的前驱或后继。
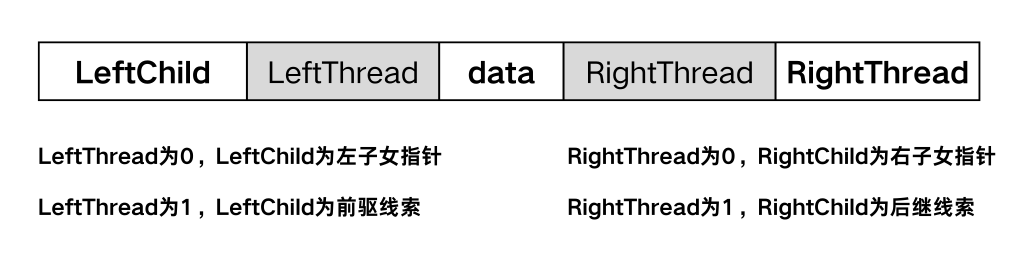
线索二叉树的结点结构
1// PointerTag 为标志
2// Link = 0 代表指针,Thread = 1 代表线索
3typedef enum {Link, Thread} PointerTag
4
5typedef struct BiThrNode {
6 ElemType data;
7 struct BiThrNode *lchild, *rchild;
8 PointerTag LTag, RTag;
9};
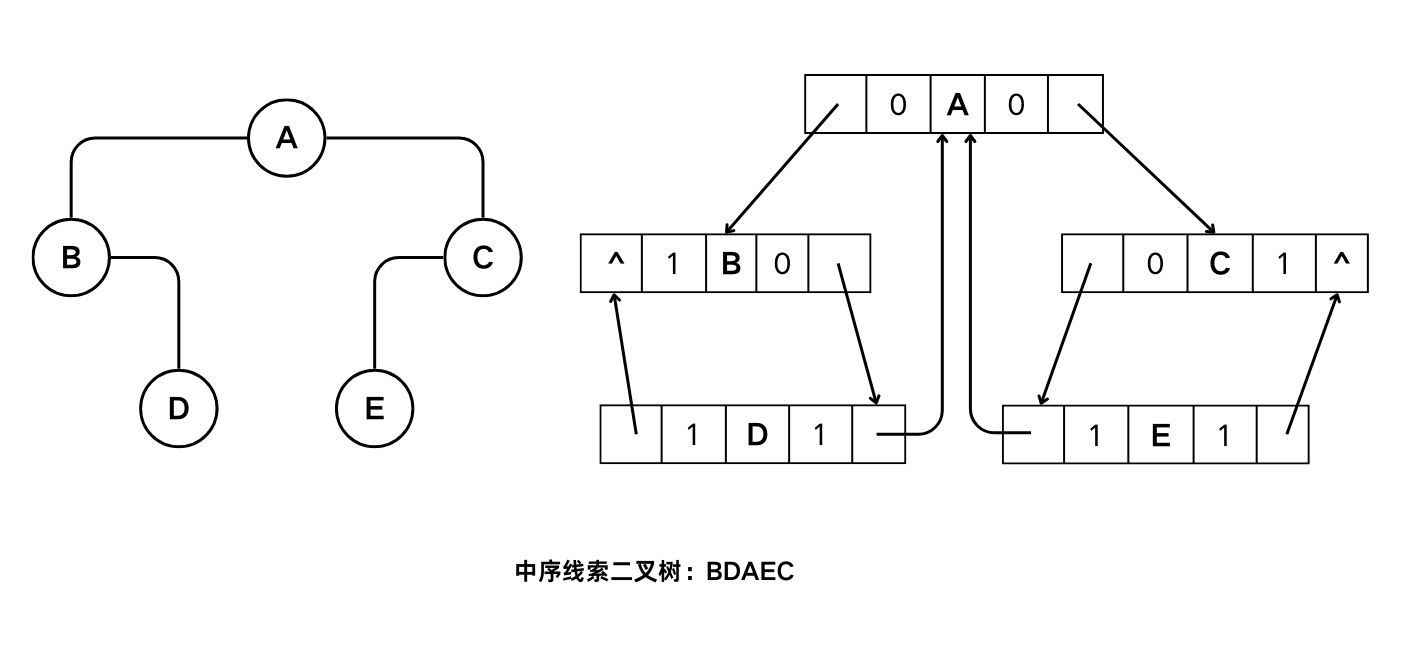
中序线索二叉树
1/* ----- 建立中序线索二叉树 ----- */
2BiThrTree *pre;
3
4bool InOrderThreading(BiThrTree* &Thrt, BiThrTree T) {
5 if(!Thrt = (BiThrTree*)malloc(sizeof(BiThrNode))) {
6 // 分配空间失败
7 return false;
8 }
9 Thrt->LTag = Link;
10 Thrt->RTag = Thread;
11 Thrt->rchild = Thrt; // 头结点右指针回指
12
13 if(!T) {
14 Thrt->lchild = Thrt // 二叉树为空,头指针也回指
15 }
16 else {
17 Thrt->lchild = T;
18 pre = Thrt; // pre指向最后一个访问过的结点
19 InThreading(T);
20 pre->RTag = Thread; // pre指向中序遍历的最后一个结点
21 pre->rchild = Thrt; // 最后一个结点的后继为头结点
22 Thrt->rchild = pre; // 头结点的右指针指向中序遍历的最后一个结点
23 }
24 return true;
25}
26
27void InThreading(BiThrTree* p) {
28 if(!p) {
29 InThreading(p->lchild);
30
31 if(!p->lchild) {
32 // 建立前驱线索
33 p->LTag = Thread;
34 p->lchild = pre;
35 }
36 if(!p->rchild) {
37 // 建立后继线索
38 pre->RTag = Thread;
39 pre->rchild = p;
40 }
41 // 保持pre为下一结点的前驱
42 pre = p;
43
44 InThreading(p->rchild);
45 }
46}
树与森林
树的存储结构
双亲表示
以一组连续空间存储树的结点,同时在结点中附设一个指针,存放双亲结点在链表中的位置。该方法利用每个结点只有一个双亲的特点,可以很方便地求出结点的双亲,但不方便得到结点的孩子。
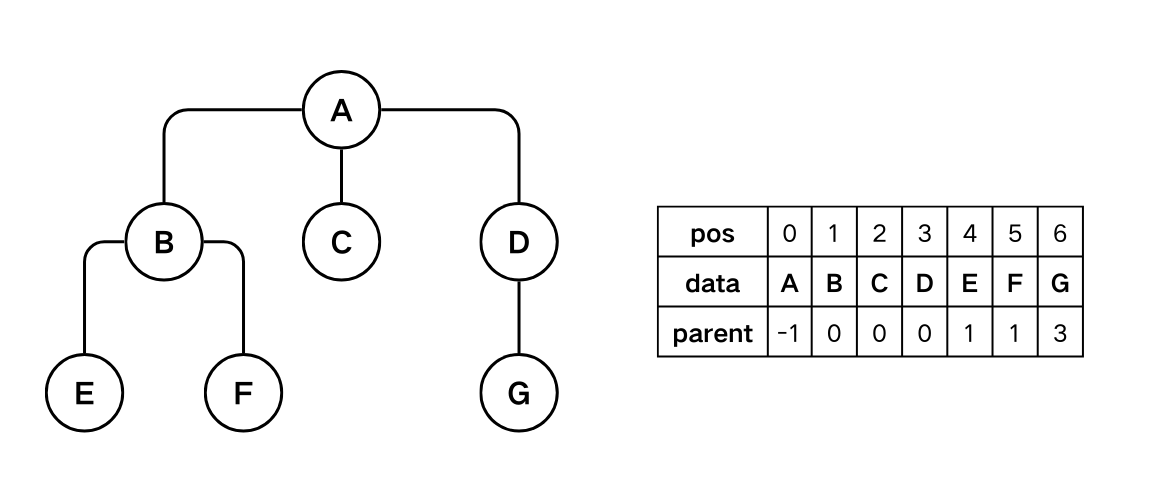
树的双亲表示
1/* ----- 树的双亲表示 ----- */
2#define MAXSIZE 100
3typedef int TreeData;
4
5typedef struct {
6 TreeData data;
7 int parent;
8} TreeNode;
9
10typedef TreeNode Tree[MAXSIZE];
孩子表示(多重链表)
将每个结点的孩子作为链表的结点链接在该结点之后,再将所有头结点组成一个线性表。
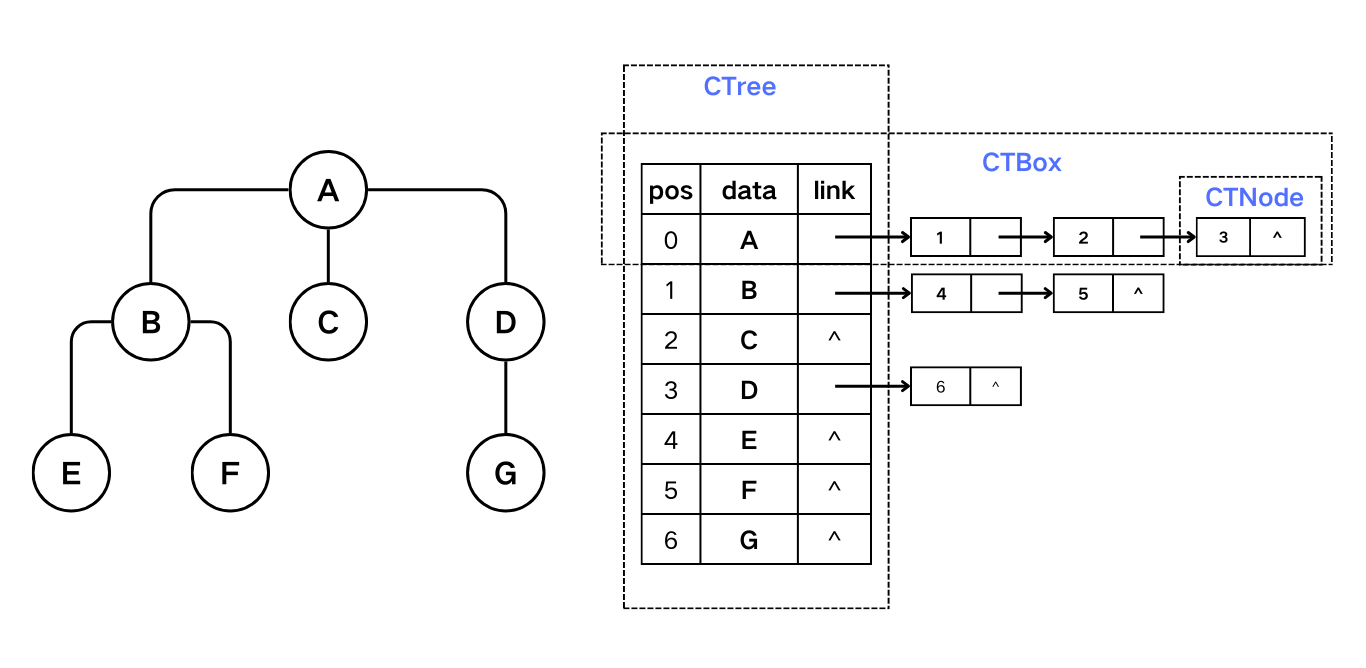
树的孩子链表表示
1/* ----- 树的孩子链表表示 ----- */
2// 孩子链表
3typedef struct CTNode {
4 int child;
5 struct CTNode *next;
6} *ChildPtr;
7s
8// 孩子链表的头结点
9typedef struct {
10 TElemType data;
11 ChildPtr FirstChild;
12} CTBox;
13
14// 孩子链表头结点的线性表
15typedef struct {
16 CTBox nodes[MAX_TREE_SIZE];
17 int n; // 结点数
18 int r; // 根的位置
19} CTree;
左子女-右兄弟表示(二叉链表)
任何一棵和树对应的二叉树,其右子树一定为空。
1/* ----- 树的二叉链表表示 ----- */
2typedef char TreeData;
3
4typedef struct node {
5 TreeData data;
6 struct node *firstChild, *nextSibling;
7} TreeNode;
8
9typedef TreeNode *Tree;
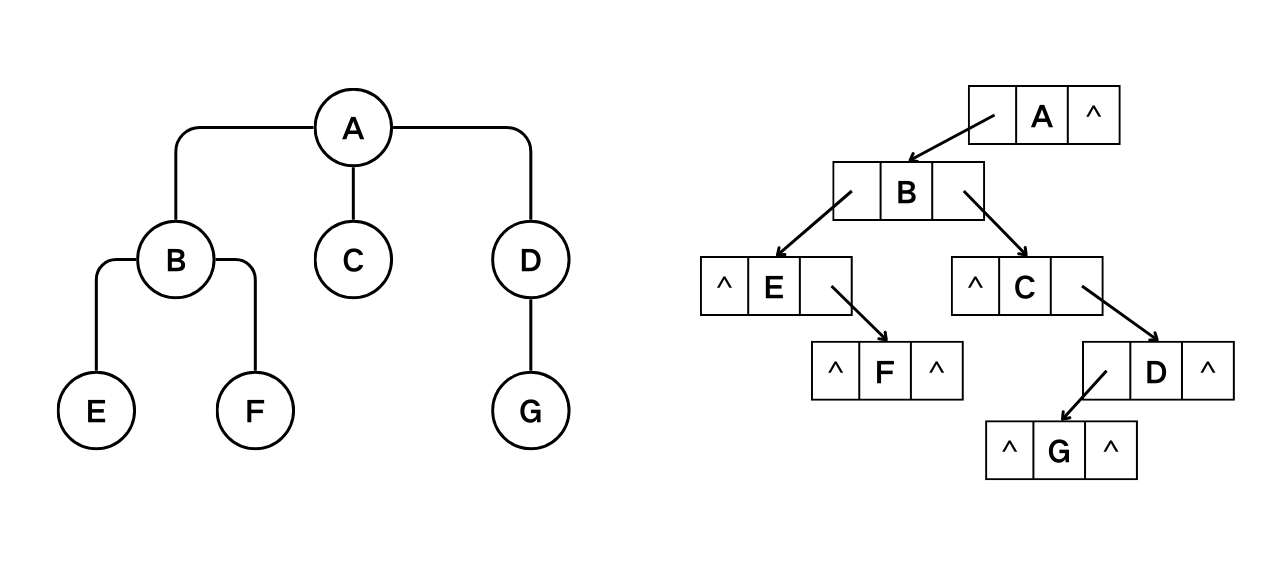
树的二叉链表表示
使用二叉链表可以方便地实现森林与二叉树的转换。
树的遍历
| 遍历方法 | 操作 | 对应二叉链表的遍历 |
|---|---|---|
| 先根次序遍历 | 当树非空时,先访问根结点,再依次先跟遍历根的各棵子树 | 前序遍历 |
| 后根次序遍历 | 当树非空时,先依次后根遍历根的各棵子树,再访问根结点 | 中序遍历 |
霍夫曼树
路径长度与霍夫曼树的定义
| 概念 | 内容 |
|---|---|
| 路径长度 | 连接两结点的路径上的分支数,记为 $PL$ |
| 外部路径长度 | 各叶结点到根结点的路径长度之和,记为 $EPL$ |
| 内部路径长度 | 各非叶结点到根结点的路径长度之和,记为 $IPL$ |
| 带权路径长度 | 各叶结点所带的权值 $w_i$ 与该结点到根结点的路径长度 $l_i$ 的乘积之和,记为 $WPL$ |
容易知道,$PL=EPL+IPL$
霍夫曼树就是带权路径长度最小的二叉树,也称作最优二叉树。
在霍夫曼树中,权值大的结点离根结点越近。
1/* ----- 霍夫曼树的定义 -----*/
2const int n = 20; // 叶结点数,初始给定的权值数量
3const int m = 2*n-1; // 结点数,所需的存储数量
4
5typedef struct {
6 float weight; // 权值
7 int parent, leftChild, rightChild;
8} HTNode;
9
10typedef HTNode HuffmanTree[m];
构造霍夫曼树
由给定的 $n$ 个权值 $\{w_0,w_1,w_2,\cdots,w_{n-1}\}$,构造具有 $n$ 棵二叉树的森林 $F=\{T_0,T_1,T_2,\cdots,T_{n-1}\}$,其中每棵二叉树 $T_i$ 只有一个带权值的根结点,其左右子树均为空。
步骤:
- 在 $F$ 中选取两棵根结点权值最小的二叉树,作为左、右子树构造一棵新的二叉树。令新的二叉树根结点的权值为其左右子树上根结点的权值之和。
- 在 $F$ 中删去这两棵二叉树。
- 把新的二叉树加入 $F$。
1/* ----- 构造霍夫曼树 ------ */
2void CreatHuffmanTree(HuffmanTree T[], float fr[]) {
3 // 将各边的权值加入数组中
4 for(int i = 0; i<n; i++) {
5 T[i].weight = fr[i];
6 }
7 // 初始化各子树
8 for(int i = 0; i<m; i++) {
9 T[i].parent = -1;
10 T[i].leftChild = -1;
11 T[i].rightChild = -1;
12 }
13
14 for (int i = 0; i<m; i++) {
15 int min1 = min2 = MAXNUM;
16 int pos1, pos2;
17 for(int j = 0; j<i; j++) {
18 if(T[j].parent == -1) {
19 // 从所有根结点中查找权值最小的两个
20 if (T[j].weight < min1) {
21 pos2 = pos1;
22 min2 = min1;
23 pos1 = j;
24 min1 = T[j].weight;
25 }
26 else if(T[j].weight < min2) {
27 pos2 = j;
28 min2 = T[j].weight;
29 }
30 }
31 }
32 T[i].leftChild = pos1; // 左子树为第一小的结点
33 T[i].rightChild = pos2; // 右子树为第二小的结点
34 T[i].weight = T[pos1].weight + T[pos2].weight;
35 T[pos1].parent = T[pos2].parent = i;
36 }
37}
霍夫曼编码
霍夫曼编码主要用于实现数据压缩。
若按照各个字符出现概率的不同而给予不同长度的编码,可以减少总编码长度。总编码长度正好等于霍夫曼树的带权路径长度。
霍夫曼编码是一种无前缀编码(都由叶结点组成,路径不会重复)。解码时不会混淆。
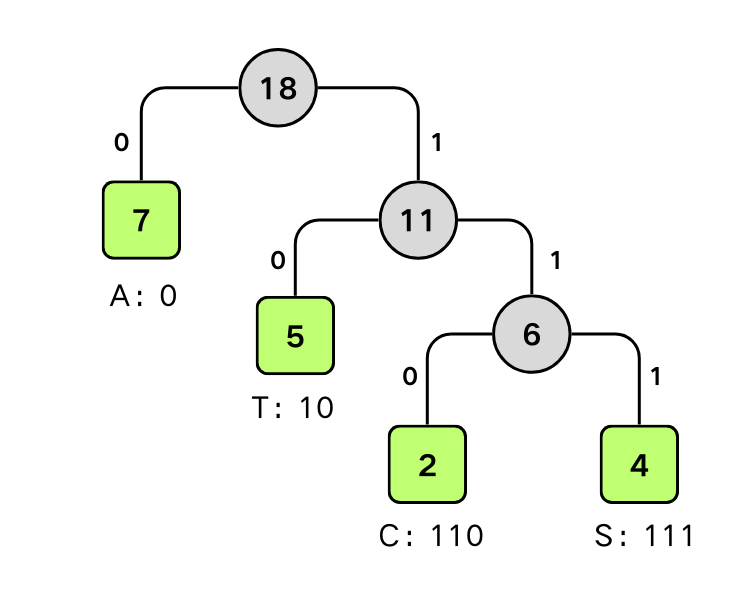
设给出一段报文:
$$CAST CAST SAT AT A TASA$$字符集合是
{C, A, S, T},各个字符出现的频度(次数)为W = {2, 7, 4, 5}按照各字符出现概率
P = {2, 7, 4, 5}为各叶结点上的权值建立霍夫曼树。左分支赋值0,右分支赋值1,可得霍夫曼编码: 霍夫曼编码
A:0 T:10 C:110 S:111