磨刀不误砍柴工!!!
实验目的:
- 掌握i386(IA-32)指令格式。
- 掌握NEMU平台的指令周期。
切换用户程序
修改工程目录下的Makefile文件,更换NEMU的用户程序:
1- USERPROG := obj/testcase/mov
2+ USERPROG := obj/testcase/mov-c
同理,将mov-c更换为testcase/src目录下的其他文件,例如add、bubble-sort等,即可执行对应的用户程序。
了解NEMU的指令集
X86系列处理器采用变长指令字结构,各种指令长度随指令功能而异。
要实现一条指令,首先你需要知道这条指令的格式和功能。格式决定如何解释,功能决定如何执行。这些信息都在 instruction set page(i386 手册第17 章)。
i386 手册中的汇编语言格式都是 Intel 格式,而 objdump(反汇编)的默认格式是 AT&T 格式,两者的源操作数和目的操作数位置不一样,千万不要把它们混淆了!
指令格式
x86指令的一般格式如下:
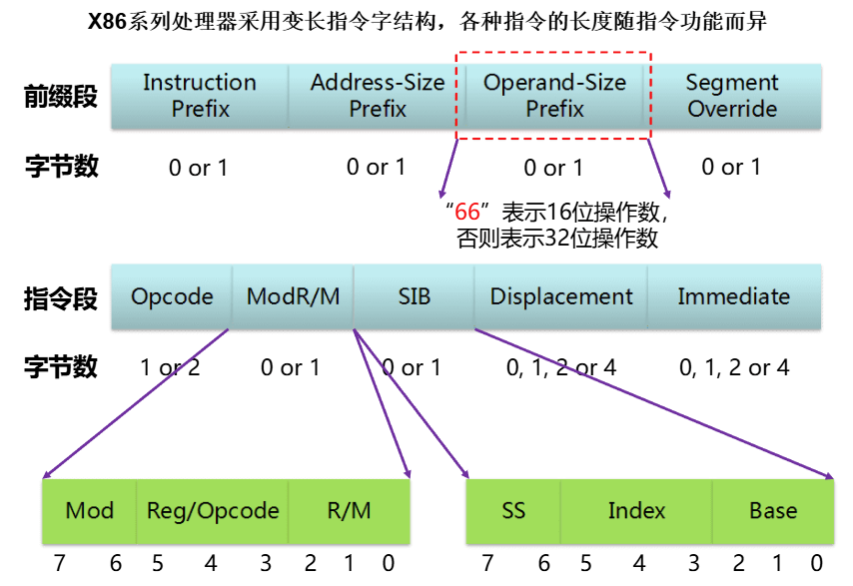
x86指令的一般格式
Opcode(操作码)必定出现,其余组成部分可能不出现。Opcode决定是否出现ModR/M;SIB、Displacement、Immediate由ModR/M决定。- 对于某些组成部分,其长度并不是固定的。
- 给定一条具体指令的二进制形式,其组成部分的划分是有办法确定的,不会产生歧义
例如对于以下指令:

指令示例
它的划分如下:

示例指令划分
ModR/M部分为什么解析出了disp32[--][--]?
ModR/M内部这一个字节的组成,分为了三个部分,具体每个部分的编码都对应着右边表内的含义,以ModR/M内的编码为基准进行查表就能够解析出对应的含义。例如例子中的
ModR/M部分编码是84(十六进制),对应二进制就是10000100,对应回格式中的部分就是Mod部分为10,R/M部分为100,二者在右边表中可以对应出一行,这一行的对应指令就是disp32[--][--]。disp32代表偏移量(displacement)为32位的,两个[--][--]就代表我们需要解析SIB中的编码部分才能得到偏移量的具体数值。
阅读Opcode Table
以mov指令的第一种形式为例:
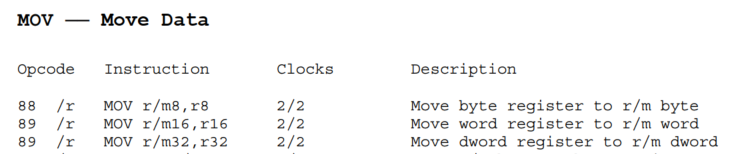
mov指令
| 列数 | 具体含义 |
|---|---|
| Description | 将一个8位寄存器中的数据传送到8位的寄存器或者内存中,其中r/m表示“寄存器或内存”。 |
| Opcode | 88表示这条指令的opcode的首字节是0x88,/r表示后面跟一个ModR/M字节,并且 ModR/M字节中的reg/opcode域解释成通用寄存器的编码。 |
| Instruction | r8表示8位寄存器;r/m8表示8位寄存器或内存,具体由mod字段决定。 |
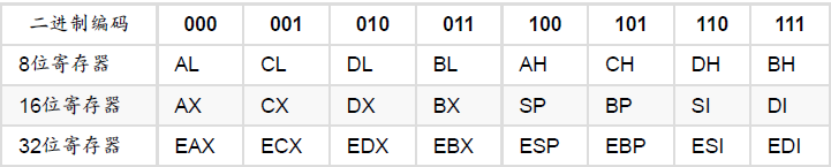
通用寄存器编码
接下来的两种形式也就不难看懂了:但这两种形式的
Opcode都是一样的,难道不会出现歧义吗?x86是通过指令一般格式中的
operand-size prefix来区分上面这两种形式的。
Operand-size prefix的编码是0x66,作用是指示当前指令需要改变操作数的长度。在 IA-32 中,通常如果这个前缀没有出现,操作数长度默认是 32 位;当这个前缀出现的时候,操作数长度就改变成16位。换句话说,如果把一个开头为
89 ...的比特串解释成指令,它就应该被解释成MOV r/m32, r32的形式;如果比特串的开头是66 89...,它就应该被解释成MOV r/m16, r16。
C语言宏定义
在C语言中,可以使用命令#define来定义宏。宏不负责检查语法的正确性。
1// 常规的宏
2#define PI 3.1415926
3// 带参数的宏
4#define putchar(x) putc(x, stdout)
5
6// 使用宏进行连接
7#define concat(x, y) x ## y
例如:
1#define make_helper(name) int name(swaddr_t eip)
这个宏定义就代表了以下的两行代码是同一个代码,我们使用的时候看到的是上面部分函数,但是程序执行的时候实际上是在执行下面的函数(实际上就是同一个函数):
1make_helper(exec)
2int exec(swaddr_t eip)
在C语言中,宏必须定义在一行中。
若需通过换行提高代码可读性,可使用
\附在每行末尾。
NEMU的指令周期
取指
核心流程
1void cpu_exec(volatile uint32_t n) {
2 ...
3
4 for(; n>0; n--) {
5 int instr_len = exec(cpu.eip); // 执行当前%eip所指向的指令
6 cpu.eip += instr_len; // %eip指向下一条指令
7 }
8
9 ...
10}
函数exec:
1make_helper(exec) { //等价于 int exec(swaddr_t eip)
2 ops_decoded.opcode = instr_fetch(eip, 1); // 表示读取一个字节的操作码
3 return opcode_table[ops_decoded.opcode](eip); // 返回一个函数
4}
其中,函数instr_fetch()负责取指:
1static inline uint32_t instr_fetch(swaddr_t addr, size_t len) {
2 return swaddr_read(addr, len);
3}
instr_fetch()从eip处提取Opcode,存储到ops_decoded.opcode中。
译码
所有指令的规则如下:
| 内容 | 规则 |
|---|---|
| 指令 | 指令名称,具体由i386手册确定 |
| 形式 | i2r,将立即数移动到寄存器 i2rm,将立即数移动到寄存器或内存 r2rm,将寄存器移动到寄存器或内存 |
| 操作数后缀 | b表示操作数长度为8,v表示无法确定操作数长度,可能是16或32 |
通过opcode_table,根据提取到的Opcode找到对应的指令处理函数(如mov_i2r_v)。
执行
- 对于同一指令的不同形式,它们的执行阶段是相同的。如
mov_i2rm和mov_rm2r,它们的执行阶段都是将源操作数存储到目标操作数中。 - 对于不同指令的同一种形式,它们的译码阶段是相同的。如
mov_i2rm和sub_rm2r,它们的译码阶段都是识别出一个立即数和一个rm操作数。 - 对于同一条指令同一种形式的不同长度,它们的译码阶段和执行阶段都非常类似。如
mov_i2rm_b,mov_i2rm_w和mov_i2rm_l。它们都是识别出一个立即数和一个rm操作数,然后把立即数存入rm操作数。
访存
访存指令
写回
指令执行完后,eip指向下一条指令。
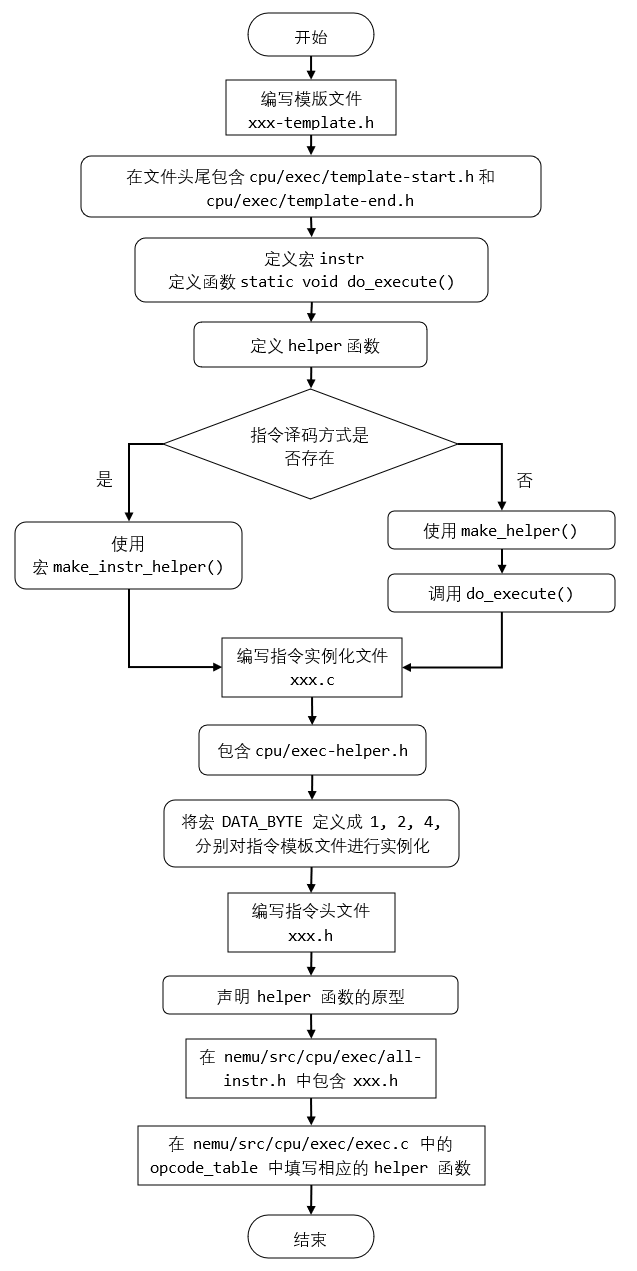
编写指令的流程
-
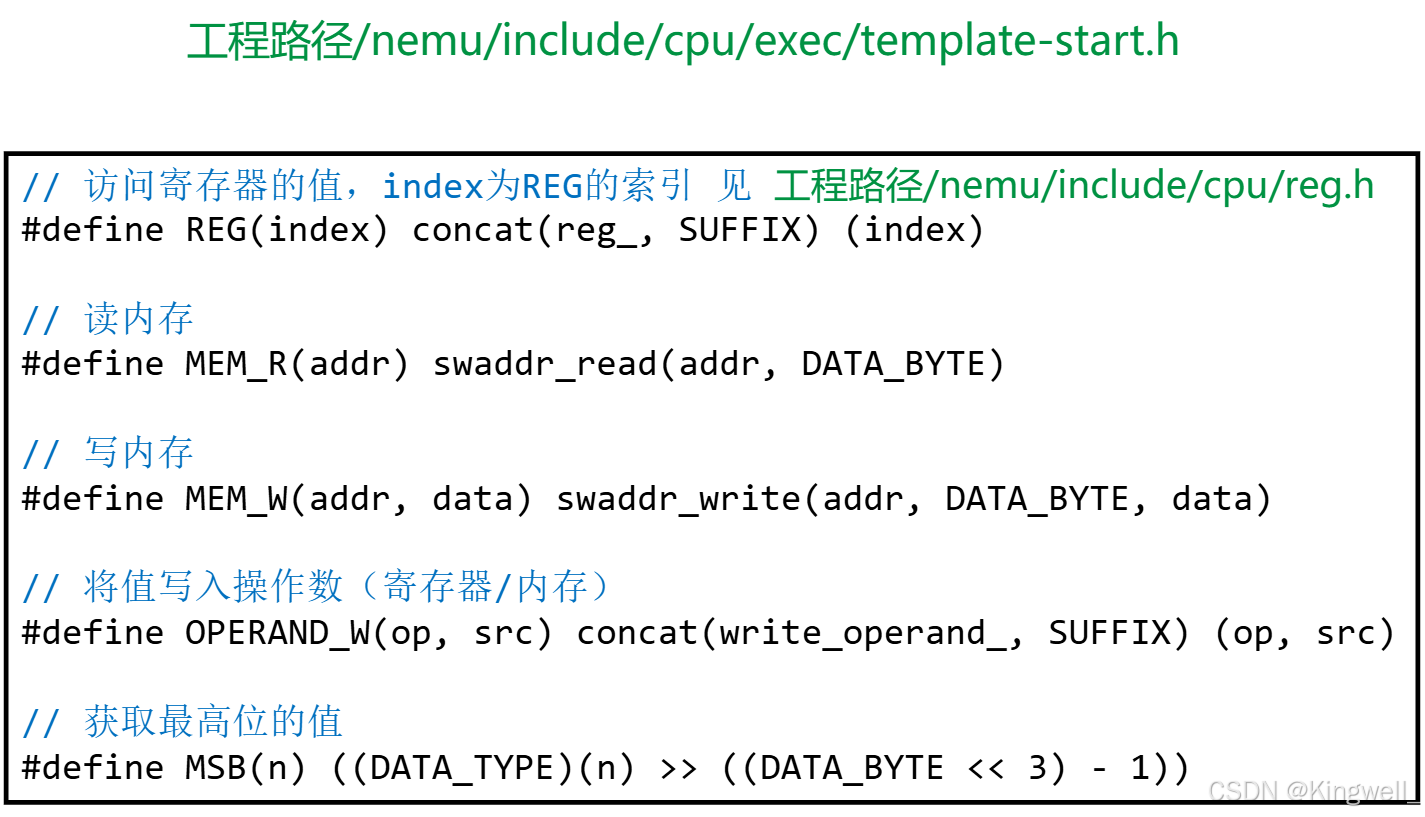
编写指令模板文件
xxx-template.h
① 在文件头尾分别包含cpu/exec/template-start.h和cpu/exec/template-end.h。
② 定义宏instr为指令名称。
③ 定义函数static void do_execute(),实现该指令的通用执行过程。
④ 定义helper函数
(1)若指令的译码方式在nemu/include/cpu/decode/decode.h中已经存在,那么可以考虑使用宏make_instr_helper()来构造helper函数(大部分 helper 函数都可以通过这种方式构造)。
(2)否则可以考虑添加相应的译码函数或者不使用make_instr_helper(), 而是直接使用make_helper()来定义helper函数,在函数体中直接进行译码,并调用do_execute()(可以参考nemu/src/cpu/exec/data-mov/xchg-template.h中的xchg_a2r指令类型。 -
编写指令实例化文件
xxx.c
① 包含cpu/exec-helper.h。
② 通过分别将宏DATA_BYTE定义成 1, 2, 4, 分别对指令模板文件xxx-template.h进行实例化。
③ 若一个helper函数只会在某些操作数长度中用到,可以在xxx-template.h中通过条件编译的功能来指定(可以参考nemu/src/cpu/exec/data-mov/xchg-template.h中的xchg_a2r指令类型)。
④ 必要时通过宏make_helper_v()定义相应的重载函数,根据指令的操作数长度前缀确定调用哪一个helper函数。 -
编写指令头文件
xxx.h,声明helper函数的原型。 -
在
nemu/src/cpu/exec/all-instr.h中包含xxx.h。 -
在
nemu/src/cpu/exec/exec.c中的opcode_table中填写相应的helper函数