排序是将一个数据元素的任意序列,重新排列成一个按关键字有序的序列的过程。
所有排序算法均使用以下结构:
1#define MAXSIZE 100
2typedef int KeyType;
3
4struct Data {
5 KeyType key;
6};
7
8struct SqList {
9 Data r[MAXSIZE+1]; // 通常 r[0] 用作辅助空间,也称作“哨兵位”
10 int length;
11};
定义函数LT()为元素比较函数:
1// 将元素从小到大排列
2bool LT(int a, int b) {
3 return a>b;
4}
5
6// 将元素从大到小排列
7bool LT(int a, int b) {
8 return a<b;
9}
插入排序
直接插入排序
核心是将一个待排序的数据插入到已排好序的有序表中,从而完成排序。
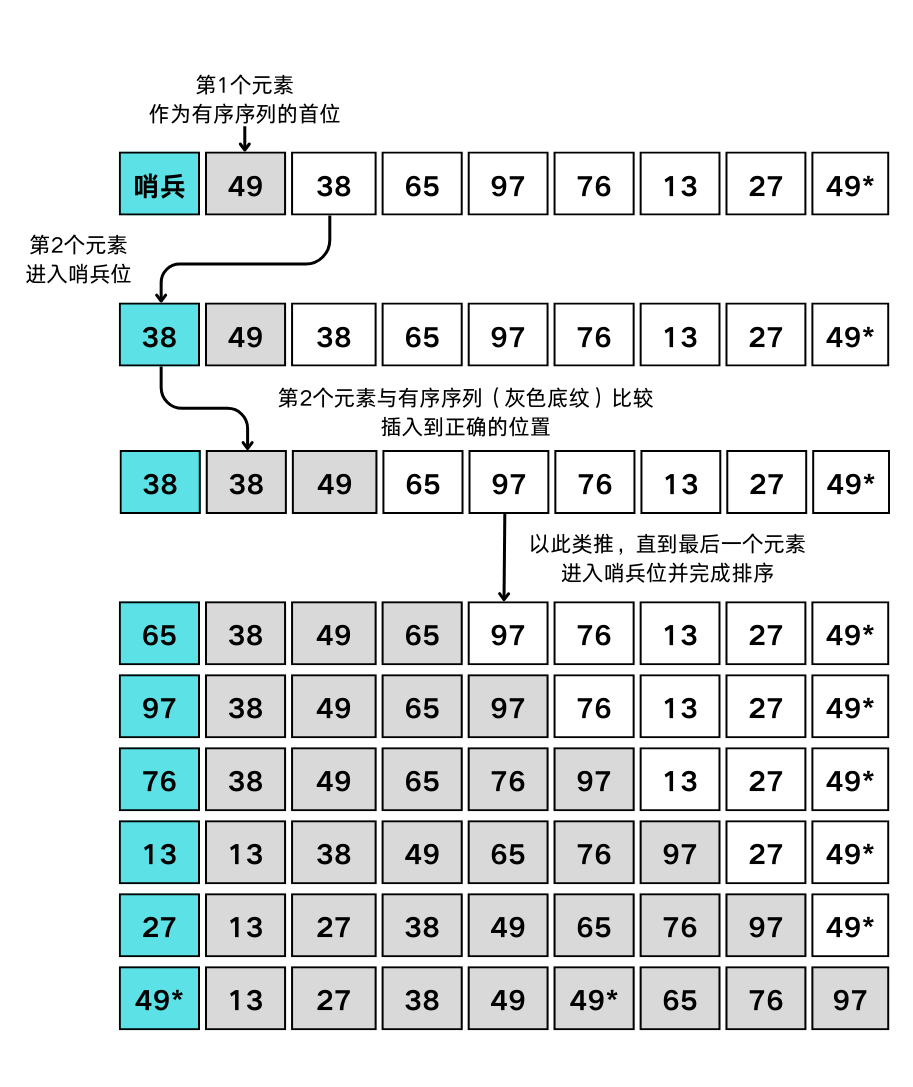
1void InsertSort(SqList &L) {
2 for (int i = 2; i<=L.length; i++) {
3 if(LT(L.r[i].key, L.r[i-1].key)) { // 将L.r[i]插入有序子表
4 L.r[0] = L.r[i]; // 复制到“哨兵”位
5 L.r[i] = L.r[i-1];
6 }
7 for (int j = i-2; LT(L.r[0].key, L.r[j].key); j--) {
8 L.r[j+1] = L.r[j]; // 记录后移
9 }
10 L.r[j+1] = L.r[0]; // 插入到正确位置
11 }
12}
希尔排序
步骤:
- 设待排序对象序列有 $n$ 个对象,首先取一个整数
gap < n作为间隔,将全部对象分为gap个子序列,所有距离为gap的对象放在同一个子序列中 在每一个子序列中分别施行直接插入排序; - 然后缩小间隔
gap,重复上述的子序列划分和排序工作; - 直到最后取
gap = 1,将所有对象放在同一个序列中排序为止。
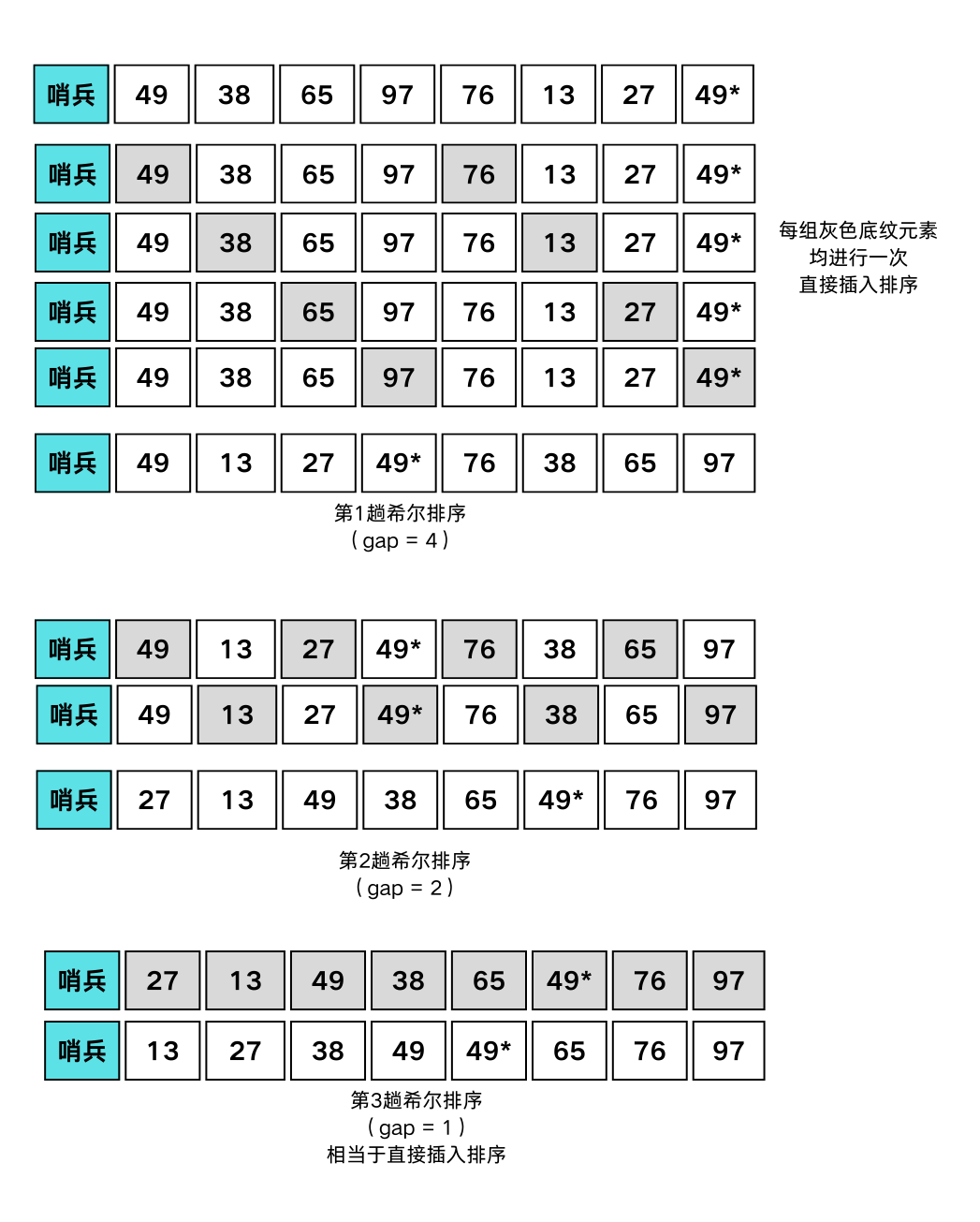
1void ShellSort(SqList &L) {
2 int i, j = 0;
3 int gap = L.length / 2;
4 while (gap >= 1) {
5 // 直接插入排序
6 for (i = gap + 1; i <= L.length; i++) {
7 L.r[0] = L.r[i];
8 for (j = i - gap; j > 0 && LT(L.r[0].key, L.r[j].key); j -= gap) {
9 L.r[j+gap] = L.r[j];
10 }
11 L.r[j+gap] = L.r[0];
12 }
13 gap /= 2;
14 }
15}
希尔排序的特点:
- 开始时
gap的值较大,但子序列中的对象较少,排序速度较快;随着gap逐渐变小,子序列中对象个数逐渐变多,但大多数对象已基本有序,所以排序速度仍然很快。时间复杂度取决于gap的取法(或称“增量”序列函数); - 对特定待排序对象序列,可准确估算比较次数和移动次数。希尔排序所需的比较次数和移动次数约为 $n^{1.3}$,当
n趋于无穷时可减少到 $n(\log n)^2$; - 希尔排序是一种不稳定的排序方法。
交换排序
基本思想:两两比较待排序对象的关键字,若为逆序,则交换之,直到所有对象都排好序为止。
冒泡排序
冒泡排序的原理是每次都将最大(或最小)的元素转移至最右侧,类似于水中的气泡不断上升的过程。
步骤:
- 设待排序对象个数为
n; - 一般地,第
i趟冒泡排序从1到n-i+1依次比较相邻两个记录的关键字,若为逆序,则交换之。 - 在一趟排序过程中没有进行过交换记录的操作,则结束,最多作
n-1趟排序。
1void BubbleSort(SqList &L) {
2 // 设置交换标记
3 bool exchange = true;
4 for(int i = 1; i < L.length && exchange; i++) {
5 // 假设未交换
6 exchange = false;
7 for(int j = 1; j < L.length-i+1; j++) {
8 if(LT(L.r[j].key, L.r[j+1].key)) {
9 // 若满足交换条件,则设置交换标记为真
10 swap(L.r[j].key, L.r[j+1].key);
11 exchange = true;
12 }
13 }
14 }
15}
冒泡排序分析:
- 最好情况:若初始序列为正序,则只执行一趟排序,做
n-1次比较,不移动记录; - 最坏情形:若初始序列为逆序,则需执行
n-1趟排序,第i趟 $(1 \leqslant i \leqslant n)$ 做n-i次比较和交换; - 时间复杂度为 $O(n^2)$;
- 冒泡排序是一个稳定的排序方法。
快速排序
基本思想:
- 选取一个记录作基准,通过一趟排序将待排记录划分为左右两个子序列,使得:左侧子序列中所有关键字都小于基准关键字,右侧子序列中所有关键字都大于或等于基准关键字;
- 基准对象则排在这两个子序列中间(这也是该对象最终应安放的位置),称为枢轴(支点);
- 然后分别对这两个子序列重复施行上述方法,直到所有的对象都排在相应位置为止。
一趟快速排序的过程:
- 设两个指针
low和high,设枢轴记录的关键字为pivotkey; - 首先从
high所指位置起向前搜索找到第一个关键字小于pivotkey的记录,并和枢轴记录互相交换 - 然后从
low所指位置起向后搜索,找到第一个关键字大于pivotkey的记录,和枢轴记录互相交换 - 重复2, 3两步直至
low == high为止。
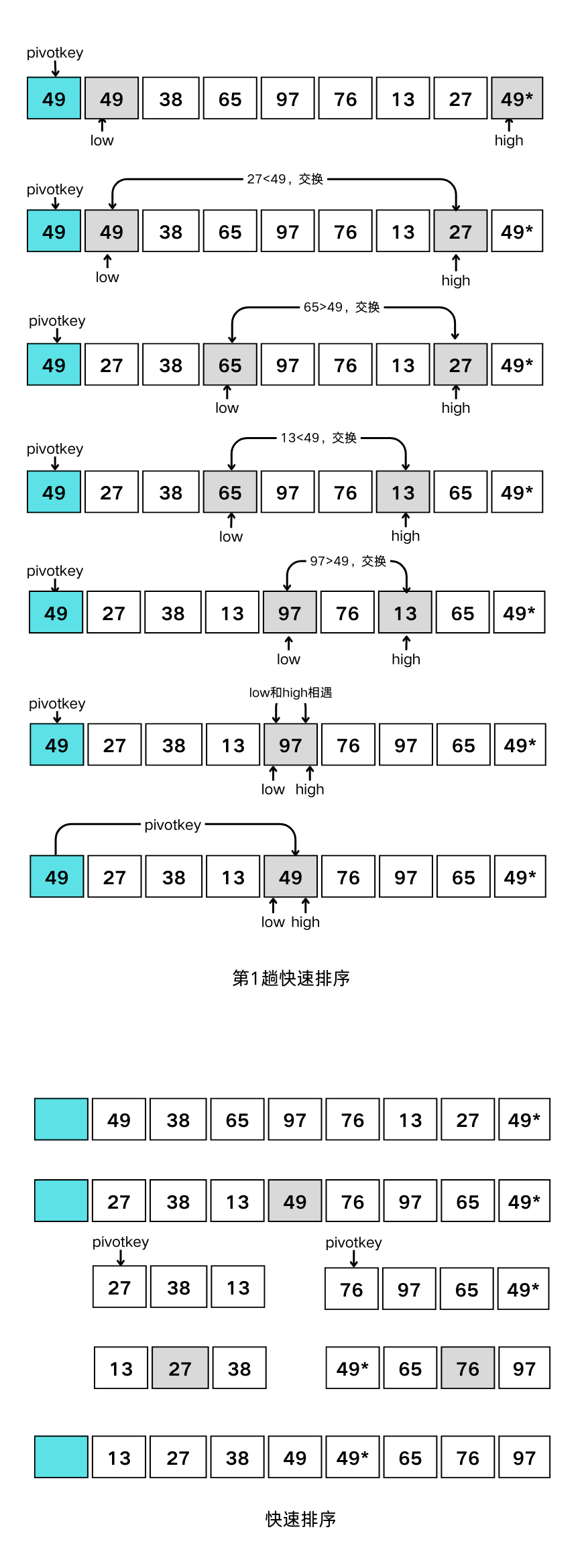
1/* ----- 一趟快速排序 ----- */
2int Partition(SqList &L, int low, int high) {
3 L.r[0] = L.r[low]; // 第一个记录作基准对象
4 KeyType pivotkey = L.r[low].key; // 枢轴记录关键字
5 while (low < high) {
6 while(low < high && L.r[high].key >= pivotkey) {
7 high-- ;
8 }
9 L.r[low] = L.r[high]; // 小于基准对象的移到区间的左侧
10
11 while(low < high && L.r[low].key <= pivotkey) {
12 low++ ;
13 }
14 L.r[high] = L.r[low]; // 大于基准对象的移到区间的右侧
15 }
16 L.r[low] = L.r[0];
17 return low;
18}
19
20/* ----- 在序列 low-high 中递归地进行快速排序 ----- */
21void Qsort(SqList &L, int low, int high) {
22 if (low < high) {
23 pivotloc = Partition(L, low, high); // 划分
24 QSort(L, low, pivotloc-1); // 左序列同样处理
25 QSort(L, pivotloc+1, high); // 右序列同样处理
26 }
27}
28
29/* ----- 主函数 ----- */
30void QuickSort(SqList &L) {
31 Qsort(L, 1, L.length);
32}
快速排序分析:
- 快速排序的平均计算时间为 $O(n\log n)$。实验结果表明:就平均计算时间而言,快速排序是所有内排序方法中最好的一个。
- 快速排序是一种不稳定的排序方法。
在C++中,快速排序可使用algorithm库中的sort函数,时间复杂度为 $O(n\log n)$。
1#include <algorithm>
2
3// 长度为n的数组
4sort(a,a+n);
5// vector容器
6sort(vector.begin(), vector.end());
选择排序
基本思想:进行n–1趟排序,每一趟在n–i+1 $(i=1,2,\cdots,n-1)$ 个记录中选取关键字最小的记录作为有序序列中第i个记录。
直接选择排序
基本步骤:
- 每一步,在
L.r[i]~L.r[n]中选择关键字最小记录; - 若它不是该组第一个记录,则将它与该组中的第一个记录对调;
- 在剩下的记录
L.r[i+1]~L.r[n]中重复执行第1、2步,直到循环结束。
1void SelectSort(SqList &L) {
2 for (int i = 1; i < L.length; i++) {
3 int k = i; // 选择具有最小的关键字
4 for(int j = i+1; j <= L.length; j++) {
5 if(L.r[j].key < L.r[k].key) {
6 k = j; // 当前最小关键字
7 }
8 }
9 if( k != i ) {
10 // 对换到第 i 个位置
11 swap(L.r[i], L.r[k]);
12 }
13 }
14}
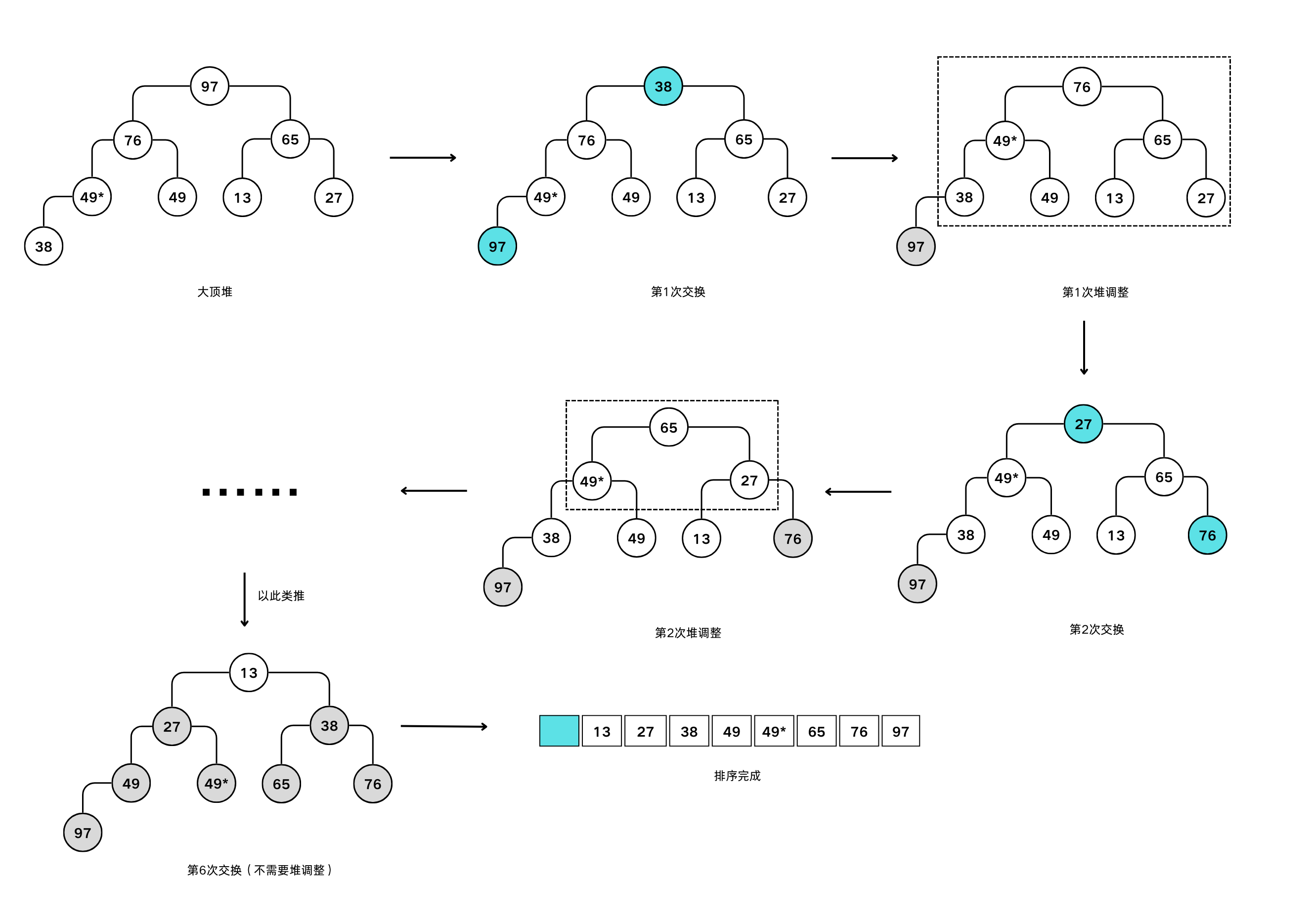
堆排序
堆的定义:设有一个关键字集合,按完全二叉树的顺序存储方式存储在一维数组中。对它们从根开始,自顶向下,同一层自左向右从
$$K_i \leqslant K_{2i} \ \&\&\ K_i \leqslant K_{2i+1}$$1开始连续编号。若满足或
$$K_i \geqslant K_{2i} \ \&\&\ K_i \geqslant K_{2i+1}$$则称该关键字集合构成一个堆。前者称为小顶堆(最小堆),后者称为大顶堆(最大堆)。
堆调整:将一无序序列看成完全二叉树,则最后一个非终端结点是第 $\displaystyle \left\lfloor \frac{n}{2} \right\rfloor$ 个元素,则从该元素开始自下向上逐步调整为大顶堆(小顶堆)。
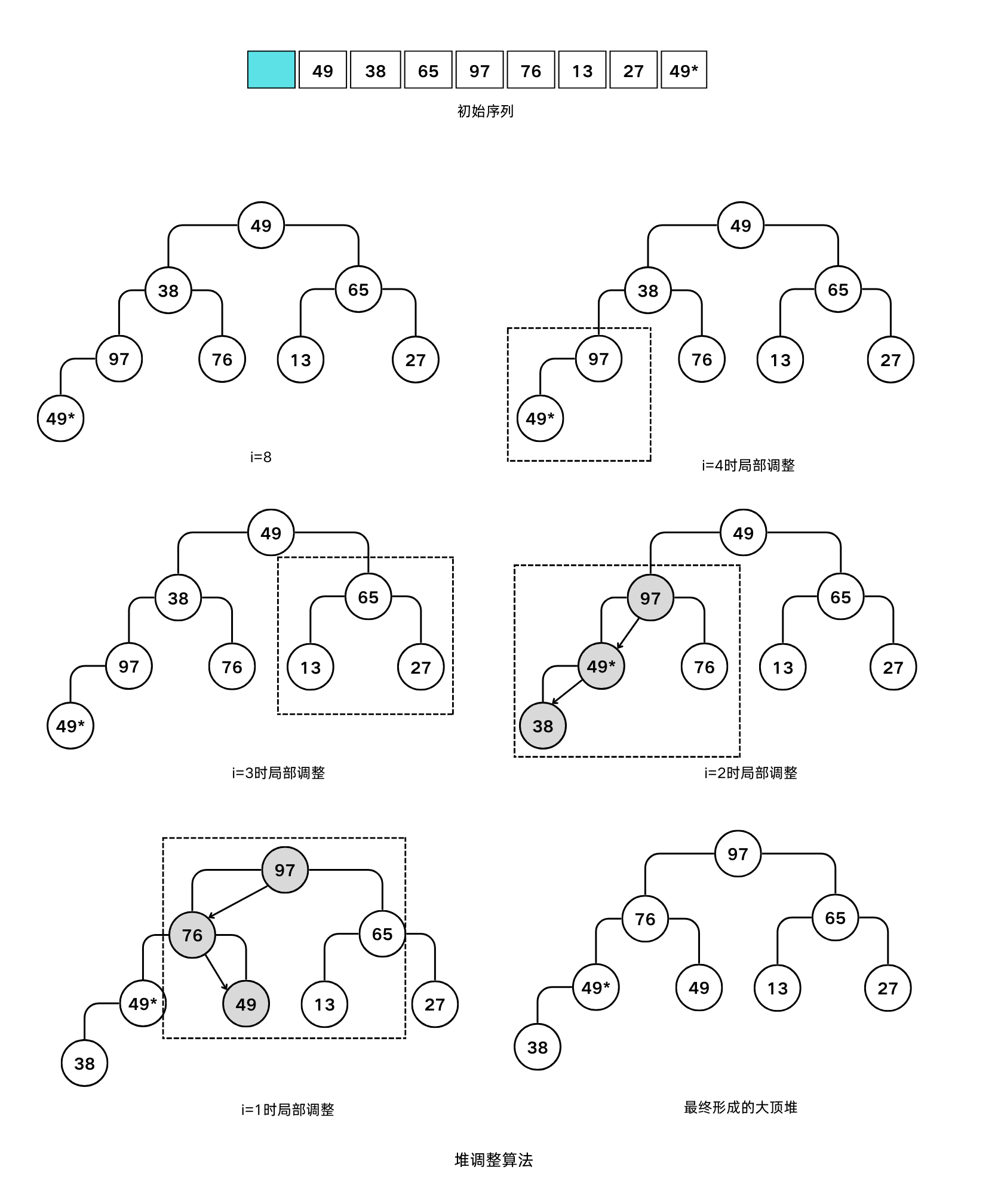
使用堆排序实现由小到大排列:
- 建立一个大顶堆,则可以交换第一和最后一个对象,最后一个对象就位;
- 而前
n–1个元素使用一次调整算法,又可成为一个大顶堆,则再交换第一和倒数第二个元素,再调整; - 依此类推可得最终序列。
1typedef SqList HeapType;
2
3/* ----- 堆调整算法 ----- */
4// 设大顶堆为 H.r[s..m],且 H.r[s] 需要调整
5void HeapAdjust(HeapType &H, int s, int m) {
6 Data rc = H.r[s];
7 for(int j = 2*s; j <= m; j *= 2) {
8 if(j < m && H.r[j].key < H.r[j+1].key) {
9 j++;
10 }
11 if(rc.key >= H.r[j].key) {
12 break;
13 }
14 H.r[s] = H.r[j];
15 s = j;
16 }
17 H.r[s] = rc;
18}
19
20/* ----- 堆排序 ----- */
21void HeapSort(HeapType &H) {
22 // 建立堆
23 for(int i = H.length/2; i > 0; i--) {
24 HeapAdjust(H, i, H.length);
25 }
26 // 排序
27 for(int i = H.length; i > 1; i--) {
28 swap(H.r[1], H.r[i]);
29 HeapAdjust(H, 1, i–1);
30 }
31}
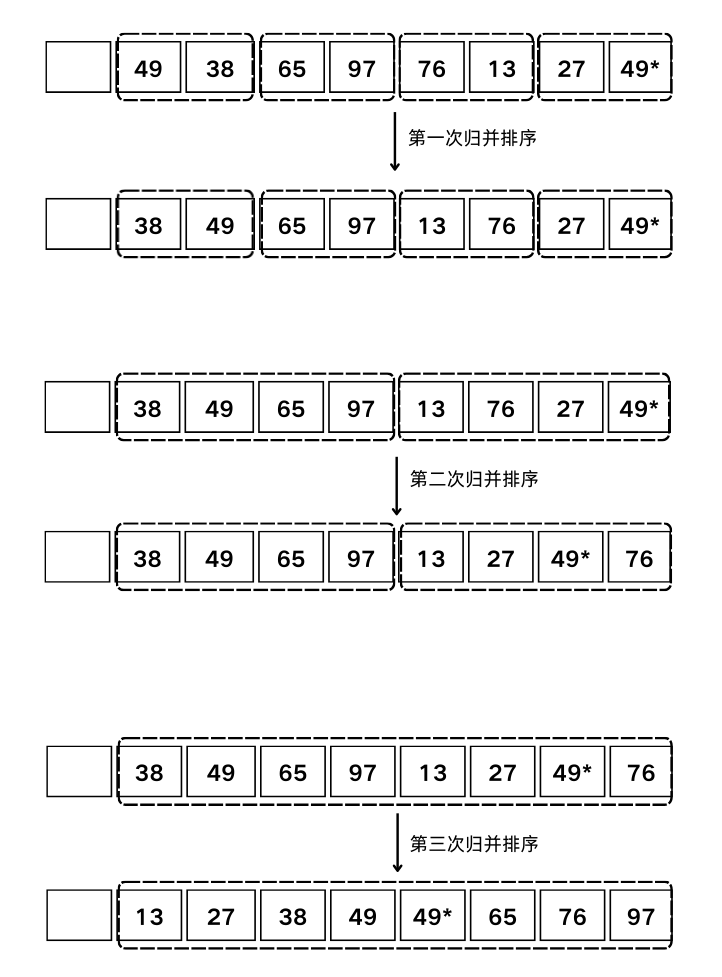
归并排序
定义:不断将两个或两个以上的有序表合并成一个新的有序表的排序方法。
常用的归并排序方法为2-路归并排序。
步骤:
- 设初始序列有 $n$ 个对象,首先把它看成是 $n$ 个长度为 $1$ 的有序子序列;
- 然后两两归并,得到 $\displaystyle \left\lceil \frac{n}{2} \right\rceil$ 个长度为 $2$ 的有序子序列(如果 $n$ 为奇数,则最后一个有序子序列的长度为 $1$);
- 再做两两归并,如此重复,最后得到一个长度为 $n$ 的有序序列。
1// 将有序的 SR[l..m] 和 SR[m+1..r] 归并为有序的 TR[l..r]
2void Merge(RcdType SR[], RcdType TR[], int l, int m, int r) {
3 int i = l, j = m + 1, k = l;
4 while (i <= m && j <= r) { // 归并
5 if (SR[i].key <= SR[j].key) {
6 TR[k] = SR[i++];
7 }
8 else {
9 TR[k] = SR[j++];
10 }
11 k++;
12 }
13 if (i <= m) {
14 TR[k..r] = SR[i..m]; // 整体复制
15 }
16 if (j <= r) {
17 TR[k..r] = SR[j..r]; // 整体复制
18 }
19}
20
21// 一趟归并排序
22void MSort (RcdType SR[], RcdType TR[], int len, int n) {
23 int i = 1; // 序列从1开始两两归并
24 while (i + 2*len – 1 <= n) {
25 Merge(SR, TR, i, i+len–1, i+2*len–1);
26 i += 2*len; // 循环两两归并
27 }
28 if (i + len <= n) { // 仍可再进行一次归并
29 Merge(SR, TR, i, i + len – 1, n);
30 }
31 else {
32 TR[i..n] = SR[i..n]; // 整体复制
33 }
34}
35
36// 2-路归并排序主程序
37void MergeSort(SqList &L) {
38 RcdType TR[L.length];
39 int len = 1;
40 while (len < L.length) {
41 MSort(L.r, TR, len, L.length);
42 L.r = TR; // 表示将TR整体复制到原序列L.r
43 len *= 2;
44 }
45}
递归形式的归并排序:
1void MSort(RcdType SR[], RcdType &TR[], int l, int r) {
2 if(l == r) {
3 TR[l] = SR[l];
4 }
5 else {
6 int m = (l+r) / 2; // 平分SR[l..r]
7 MSort(SR, TR1, l, m); // 对左侧进行归并排序
8 MSort(SR, TR1, m+1, r); // 对右侧进行归并排序
9 Merge(TR1, TR, l, m, r); // 合并左右两个有序序列
10 }
11}
12
13// 对顺序表L作归并排序
14void MergeSort(SqList &L) {
15 MSort(L.r, L.r, 1, L.length);
16}
桶排序
桶排序的时间复杂度为 $O(n)$,适用于数据范围较小且已知、数据容量大的排序场景。它利用值域小的特点,可以用一个数组(桶)记录各类数据出现的次数,然后下标就可以自动排序了。
1int n,m; // n为数据的个数,m为数据的种数
2int a[n], bucket[m];
3
4void bucket_sort(int a[], int bucket[], int n, int m) {
5 for(int i = 0; i < n; i++) {
6 bucket[a[i]]++ ; // 记录元素a[i]出现的次数,放进编号为a[i]的桶中
7 }
8
9 for(int i = 0; i < m; i++) {
10 // 遍历每个桶,第i个桶中的元素代表对应的i元素出现的次数
11 for(int j = 0; j < bukket[i]; j++) {
12 cout << i << ' ';
13 }
14 }
15}
各种排序的复杂度比较:
| 排序方法 | 比较次数 | 移动次数 | 稳定性 | 额外存储空间 |
|---|---|---|---|---|
| 直接插入排序 | $O(n) \sim O(n^2)$ | $0 \sim O(n^2)$ | 稳定 | $1$ |
| 折半插入排序 | $O(n\log n)$ | $0 \sim O(n^2)$ | 稳定 | $1$ |
| 冒泡排序 | $O(n) \sim O(n^2)$ | $0 \sim O(n^2)$ | 稳定 | $1$ |
| 快速排序 | $O(n\log n) \sim O(n^2)$ | $O(n\log n) \sim O(n^2)$ | 不稳定 | $\log n \sim n^2$ |
| 直接选择排序 | $O(n^2)$ | $0 \sim O(n)$ | 不稳定 | $1$ |
| 堆排序 | $O(n\log n)$ | $O(n\log n)$ | 不稳定 | $1$ |
| 归并排序 | $O(n\log n)$ | $O(n\log n)$ | 稳定 | $n$ |