你说得对,但是
NEMU是一个基于X86-64处理器模拟的IA-32操作系统。NEMU运行在一个被称作Docker的容器,在这里,被容器选中的人将被授予gcc,导引C语言之力。你将扮演一位名为Debug的神秘用户,编写众多C语言程序,在调试中找出FAIL的原因,同时逐步发掘Hit Bad Trap的真相。
目标:制作一个32位的操作系统
什么是NEMU
在X86-64处理器的机器上模拟一个32位操作系统(一个用来执行其它程序的程序!),它包括4个连贯的实验内容:
| 阶段 | 任务 |
|---|---|
| PA1 | 简易调试器 |
| PA2 | 指令系统 |
| PA3 | 存储管理 |
| PA4 | 中断与I/O |
认识NEMU
NEMU的结构
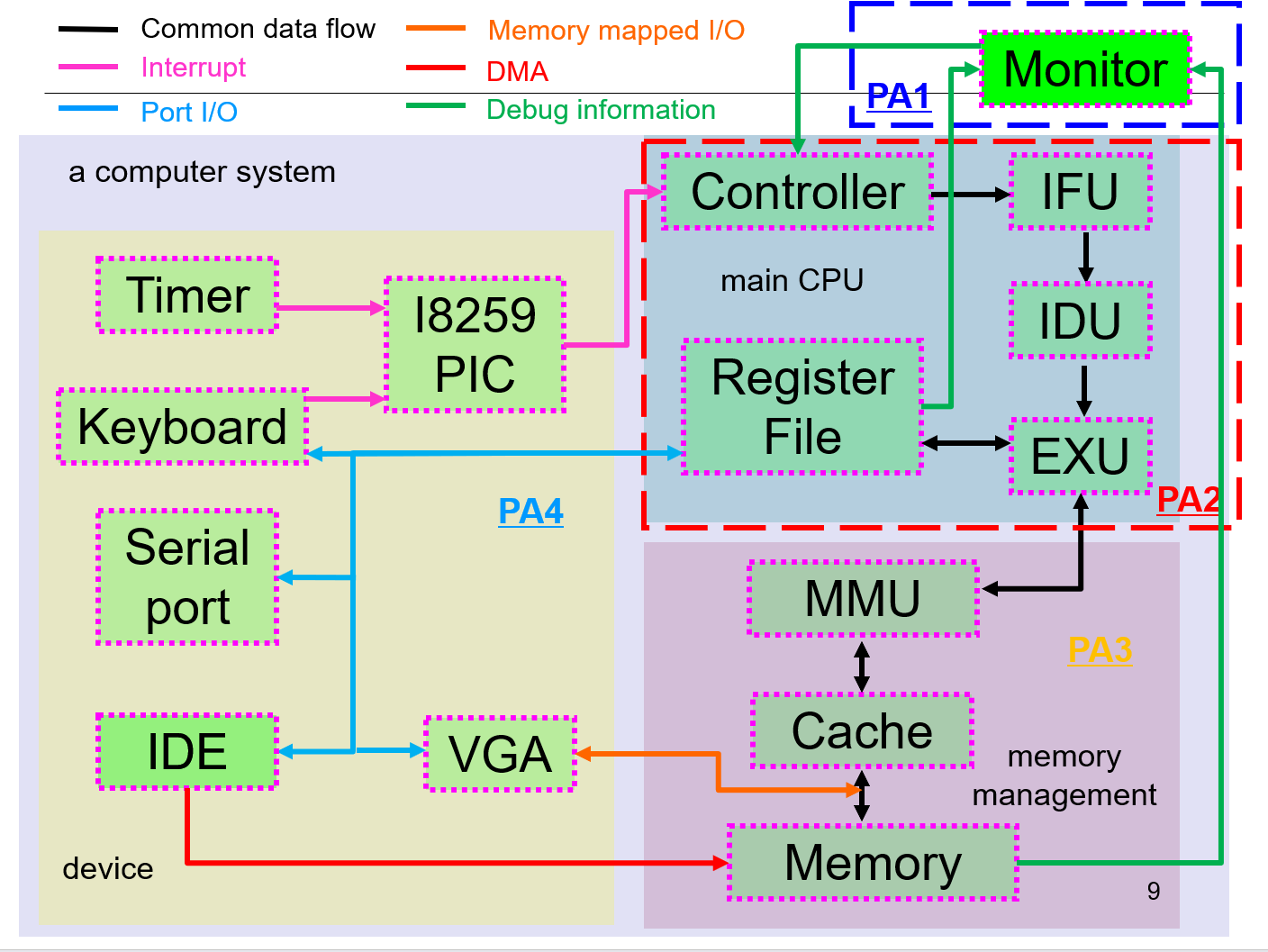
NEMU的结构
调试器操作指令集
在nemu/src/monitor/debug/ui.c中定义了调试器的结构:
1static struct {
2 char *name;
3 char *description;
4 // 函数指针,可指向*name,*description
5 int (*handler) (char *);
6} cmd_table [] = {
7 { "help", "Display informations about all supported commands", cmd_help },
8 { "c", "Continue the execution of the program", cmd_c },
9 { "q", "Exit NEMU", cmd_q },
10
11 /* TODO: Add more commands */
12 /* 接下来若想定义新的操作,格式为
13 { "name", "description", function},
14 */
15};
几个有用的函数
| 函数 | 作用 |
|---|---|
Log() |
printf()的升级版,专门用来输出调试信息,同时还会输出使用Log()所在的源文件,行号和函数,当输出的调试信息过多的时候,可以很方便地定位到代码中的相关位置 |
Assert() |
assert()的升级版,当测试条件为假时,在assertion fail之前可以输出一些信息 |
panic() |
用于输出信息并结束程序,相当于无条件的assertion fail |
swaddr_read() / swaddr_write() |
访问模拟的内存 |
strtok() |
一个简单的字符串分割工具,用于解析命令 |
sscanf() |
可以从字符串中读入格式化的内容, 使用它有时候可以很方便地实现字符串的解析 |
PA1:简易调试器
- 机器永远是对的!
- 未经过测试的每行代码永远是错误的!
- RTFM!(阅读手册!)
实现正确的寄存器结构体
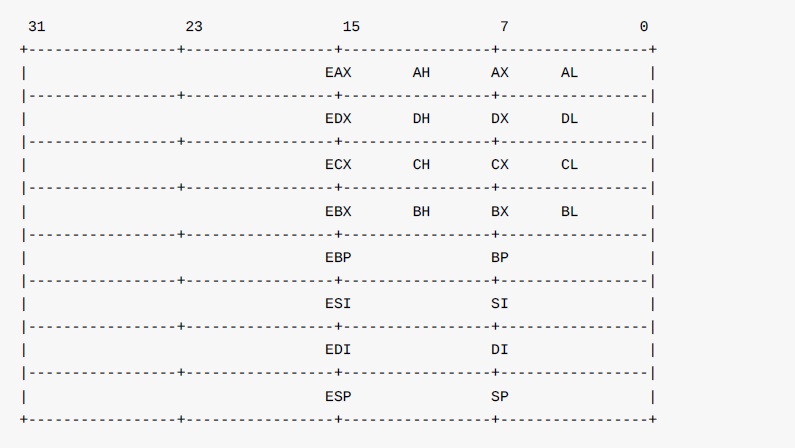
寄存器
在/nemu/include/cpu/reg.h中,原寄存器结构体定义为:
1typedef struct {
2 struct {
3 uint32_t _32;
4 uint16_t _16;
5 uint8_t _8[2];
6 } gpr[8];
7
8 /* Do NOT change the order of the GPRs' definitions. */
9 uint32_t eax, ecx, edx, ebx, esp, ebp, esi, edi;
10 ...
11} CPU_state;
使用结构体,每一个寄存器均独立存在,而X86系统的寄存器是共享的,例如 %eax 的后16位即为 %ax。因此应使用联合体的形式定义寄存器,这样对 %ax 操作时也会相应地改变 %eax 的值。
1typedef struct {
2 union {
3 union {
4 uint32_t _32;
5 uint16_t _16;
6 uint8_t _8[2];
7 } gpr[8];
8
9 /* Do NOT change the order of the GPRs' definitions. */
10 struct {
11 uint32_t eax, ecx, edx, ebx, esp, ebp, esi, edi;
12 };
13 };
14 ...
15} CPU_state;
实现调试器的功能
回顾nemu/src/monitor/debug/ui.c中对调试器的定义,需增加新的操作指令。
| 指令名 | 示例 | 功能 |
|---|---|---|
si |
si 10 |
单步执行 |
info |
info r |
打印寄存器状态 |
info w |
打印监视点状态 | |
x |
x N EXPR |
扫描内存 |
p |
p EXPR |
表达式求值 |
w |
w EXPR |
设置监视点 |
d |
d N |
删除监视点 |
1static struct {
2 char *name;
3 char *description;
4 int (*handler) (char *);
5} cmd_table [] = {
6 ...
7 // 定义单步执行操作,关键字为 si,以此类推
8 { "si", "Single step execution", cmd_si },
9 { "info", "Show register or monitor's infomation", cmd_info },
10 { "x", "Scan Memory", cmd_x },
11 ...
12};
单步执行
在nemu/src/monitor/debug/ui.c中定义新的操作函数:
1static int cmd_si(char *args) {
2 char *arg = strtok(NULL, " "); // 获取第二个字符
3 int step = 0; // 待操作步数
4 int i = 0;
5
6 if (arg == NULL) {
7 cpu_exec(1);
8 }
9 else {
10 sscanf(arg, "%d", &step); // 将arg转换为整型数
11 if (step <= 0) {
12 printf("Illegal input!");
13 }
14 else {
15 for(; i<step; i++) {
16 cpu_exec(1);
17 }
18 }
19 }
20 return 0;
21}
报错请查看:
- 使用循环时,循环变量的初始化应在循环结构之前,否则会报错:
1nemu/src/monitor/debug/ui.c:55: error: 'for' loop initial declarations are only allowed in C99 mode
2nemu/src/monitor/debug/ui.c:55: note: use option -std=c99 or -std=gnu99 to compile your code
- 读取函数应使用
sscanf。
打印寄存器状态
同理,定义操作函数cmd_info
1static int cmd_info(char *args) {
2 char *arg = strtok(NULL, " "); // 获取第二个字符
3 int i = 0;
4
5 if (*arg == 'r') { // 参数为'r'时打印寄存器的值
6 for(; i<8; i++) {
7 // 打印eax, ecx, edx, ebx, esp, ebp, esi, edi 8个寄存器
8 printf("%s\t\t", regsl[i]); // 打印寄存器名称
9 // 先打印16进制值,再打印10进制值(仿GDB)
10 // "\t" 为制表符,让输出更美观
11 printf("0x%08x\t\t%d\n", cpu.gpr[i]._32, cpu.gpr[i]._32);
12 }
13 // 打印%eip 寄存器
14 printf("eip\t\t0x%08x\t\t%d\n", cpu.eip, cpu.eip);
15 }
16 else {
17 printf("Illegal input!\n");
18 }
19
20 return 0;
21}
扫描内存
1static int cmd_x(char *args) {
2 char *arg_1 = strtok(NULL, " "); // 获取第1个参数 N
3 char *arg_2 = strtok(NULL, " "); // 获取第2个参数 EXPR
4 int i = 0;
5 int j = 0;
6
7 int N;
8 swaddr_t address;
9
10 sscanf(arg_1, "%d", &N);
11 sscanf(arg_2, "%x", &address); // 获取起始内存地址
12
13 for(; i<N; i++) {
14 // 每行打印4个值
15 if (j%4 == 0) {
16 printf("0x%x:", address);
17 }
18
19 // 每4字节打印一个值
20 printf("0x%08x ", swaddr_read(address, 4));
21 address += 4;
22 j++;
23
24 // 4个值后换行
25 if (j%4 == 0) {
26 printf("\n");
27 }
28 }
29
30 printf("\n");
31 return 0;
32}
表达式求值
阶段1:词法分析
- 定义
token
在/nemu/src/monitor/debug/expr.c中,观察token结构体,它包含两个数据type和str:
1typedef struct token {
2 int type; // 记录token的类型
3 char str[32]; // 记录token的具体数据
4} Token;
容易发现,当
token为+, -, &等单运算符时,只需要记录它的type即可,因为它们的type唯一标识了各自的具体数据。
在/nemu/src/monitor/debug/expr.c的列举类中,定义token的类型。
1enum {
2 NOTYPE = 256,
3 NUM = 1, // 10进制数
4 REGISTER = 2, // 寄存器
5 HEX = 3, // 16进制数
6 EQ = 4, // 相等
7 NOTEQ = 5, // 不相等
8 OR = 6, // 或运算
9 AND = 7, // 与运算
10 POINT, // 指针
11 NEG
12
13 /* TODO: Add more token types */
14
15};
定义了枚举类后,相应的字段和数字就确定了唯一对应的关系。例如,type = NUM和type = 1均表示10进制整数。
- 定义正则表达式
在/nemu/src/monitor/debug/expr.c中,定义正则表达式:
1static struct rule {
2 char *regex;
3 int token_type;
4} rules[] = {
5
6 /* TODO: Add more rules.
7 * Pay attention to the precedence level of different rules.
8 */
9
10 {" +", NOTYPE}, // spaces 空格
11
12 {"\\+", '+'}, // plus 运算符
13 {"\\-", '-'},
14 {"\\*", '*'},
15 {"\\/", '/'},
16
17 {"\\$[a-z]+", REGISTER}, // 数据
18 {"0x[0-9a-fA-F]+", HEX},
19 {"[0-9]+", NUM},
20
21 {"==", EQ}, // equal
22 {"!=", NOTEQ},
23
24 {"&&", AND}, // 逻辑运算符
25 {"\\|\\|", OR},
26 {"!", '!'},
27
28 {"\\(", '('}, // 括号
29 {"\\)", ')'},
30};
正则表达式的作用是识别当前表达式的具体内容。例如,对于表达式4 + 3 * ( 2 - 1 ),正则表达式的识别结果应为:

识别token
- 识别
token
在/nemu/src/monitor/debug/expr.c中的make_token函数可以帮助我们实现这一工作。
1static bool make_token(char *e) {
2 ...
3 while(e[position] != '\0') {
4 ...
5 for(i = 0; i < NR_REGEX; i ++) {
6 ...
7 // 清空token值,防止每次运算相互干扰
8 int j = 0;
9 for(; j < 32; j++) {
10 tokens[nr_token].str[j] = '\0';
11 }
12
13 // tokens.type的赋值函数
14 switch(rules[i].token_type) {
15 case 256:
16 break;
17
18 // 输入10进制数、寄存器、16进制数
19 case NUM:
20 tokens[nr_token].type = NUM;
21 strncpy(tokens[nr_token].str, &e[position - substr_len], substr_len);
22 nr_token++;
23 break;
24
25 // REGISTER,HEX,EQ,NOTEQ,AND,OR与之类似
26
27 ...
28
29 // 输入单运算符
30 case '+':
31 tokens[nr_token].type = '+';
32 nr_token++;
33 break;
34
35 // -, *, /, !, (, ) 与之类似
36
37 ...
38
39 default:
40 assert(0);
41 }
42 break;
43 }
44 }
45}
以其中一个为例:
1case NUM:
2 // token的类型为NUM
3 tokens[nr_token].type = NUM;
4 // 将sub_strlen长度的值存储到tokens.str
5 strncpy(tokens[nr_token].str, &e[position - substr_len], substr_len);
6 // 开始读取下一个token
7 nr_token++;
8 // 跳出switch循环
9 break;
阶段2:表达式求值
- 判断表达式括号匹配
1bool check_parentheses(int p, int q) {
2 int a = 0; // 记录表达式token下标
3 int i = 0, j = 0; // 分别记录左、右括号总数
4
5 // 检查表达式首尾是否为括号
6 if(tokens[p].type == '(' || tokens[q].type == ')') {
7 for(a = p; a<=q; a++) {
8 if(tokens[a].type == '(') {
9 i++;
10 }
11 if(tokens[a].type == ')') {
12 j++;
13 }
14 if(a != q && i == j) {
15 // 排除例如 (a+b)) 这种情况
16 return false;
17 }
18 }
19
20 if(i == j) {
21 // 左右括号数量相等,正确
22 return true;
23 }
24 else {
25 // 数量不等,错误
26 return false;
27 }
28 }
29
30 return false;
31}
- 寻找主操作符
dominant operator(主操作符)是表达式中最后参与运算的运算符,根据运算符优先级可知:
- 非运算符的
token不是dominant operator。 - 出现在一对括号中的
token不是dominant operator。注意到这里不会出现有括号包围整个表达式的情况,因为这种情况已经在check_parentheses()相应的if块中被处理了。 dominant operator的优先级在表达式中是最低的。这是因为dominant operator是最后一步才进行的运算符。- 当有多个运算符的优先级都是最低时,根据结合性,最后被结合的运算符才是
dominant operator。一个例子是1 + 2 + 3,它的dominant operator应该是右边的+。
找到主操作符后,表达式的运算可归结为主操作符两侧数的运算。这也就意味着该问题满足了分治的基本条件:一个问题可分解为若干个与原问题结构相同的子问题。
参阅此处:分治法
1int dominant_operator(int p, int q) {
2 int step = 0;
3 int op = -1;
4 int i = 0; // 记录token下标
5 int pri = 0; // 记录当前操作符优先级
6
7 for(i = p; i <= q; i++) {
8 if(tokens[i].type == '(') {
9 step ++;
10 }
11 else if(tokens[i].type == ')') {
12 step --;
13 }
14
15 if(step == 0) {
16 if(tokens[i].type == OR) {
17 if(pri < 51) {
18 op = i;
19 pri = 51;
20 }
21 }
22 else if(tokens[i].type == AND) {
23 if(pri < 50) {
24 op = i;
25 pri = 50;
26 }
27 }
28 else if(tokens[i].type == EQ || tokens[i].type == NOTEQ) {
29 if(pri < 49) {
30 op = i;
31 pri = 49;
32 }
33 }
34 else if(tokens[i].type == '+' || tokens[i].type == '-') {
35 if(pri < 48) {
36 op = i;
37 pri = 48;
38 }
39 }
40 else if(tokens[i].type == '*' || tokens[i].type == '/') {
41 if(pri < 46) {
42 op = i;
43 pri = 46;
44 }
45 }
46 }
47 else if(step < 0) {
48 return -2;
49 }
50 }
51 return op;
52}
- 递归计算表达式的值
这里运用的就是分治算法。
1uint32_t eval(int p, int q) {
2 int result = 0;
3 int op = 0;
4 int val1, val2;
5
6 // 表达式左侧超过右侧,错误
7 if (p > q) {
8 assert(0);
9 }
10
11 // 表达式左侧等于右侧,说明为单个数字
12 else if (p == q) {
13 // 处理10进制数
14 if (tokens[p].type == NUM) {
15 sscanf(tokens[p].str, "%d", &result);
16 return result;
17 }
18
19 // 处理16进制数
20 else if (tokens[p].type == HEX) {
21 int i = 2;
22 while(tokens[p].str[i] != 0) {
23 result *= 16;
24 if (tokens[p].str[i] <= '9') {
25 // 16进制为0-9
26 result += tokens[p].str[i] - '0';
27 }
28 else {
29 // 16进制为a-f
30 result += tokens[p].str[i] - 'a' + 10;
31 }
32 i++;
33 }
34 return result;
35 }
36
37 // 处理寄存器
38 else if (tokens[p].type == REGISTER) {
39 if (!strcmp(tokens[p].str, "$eax")) {
40 return cpu.eax;
41 }
42
43 // 剩下的寄存器使用相同的处理办法
44
45 ...
46
47 else {
48 return 0;
49 }
50 }
51 else {
52 assert(0);
53 }
54 }
55
56 // 表达式两侧不等,但是括号匹配,去掉括号
57 else if (check_parentheses(p, q) == true) {
58 return eval(p + 1, q - 1);
59 }
60
61 // 正常表达式
62 else {
63 // 寻找主操作符
64 op = dominant_operator(p, q);
65
66 if (op == -2) {
67 assert(0);
68 }
69
70 // 处理一元运算符
71 else if (op == -1) {
72 // 处理逻辑非运算,如 !1
73 if (tokens[p].type == '!') {
74 sscanf(tokens[q].str, "%d", &result);
75 return !result;
76 }
77
78 // 之后将在此处实现负数运算和指针解引用
79
80 }
81
82 // 计算主操作数两侧表达式值
83
84 val1 = eval(p, op - 1); // 计算主操作数左侧表达式
85 val2 = eval(op + 1, q); // 计算主操作数右侧表达式
86
87 switch (tokens[op].type) {
88 case '+' :
89 return val1 + val2;
90
91 // -, *, / , OR, AND, EQ, NOTEQ运算以此类推
92
93 ...
94
95 default :
96 assert(0);
97 }
98 }
99 return 0;
100}
举例:
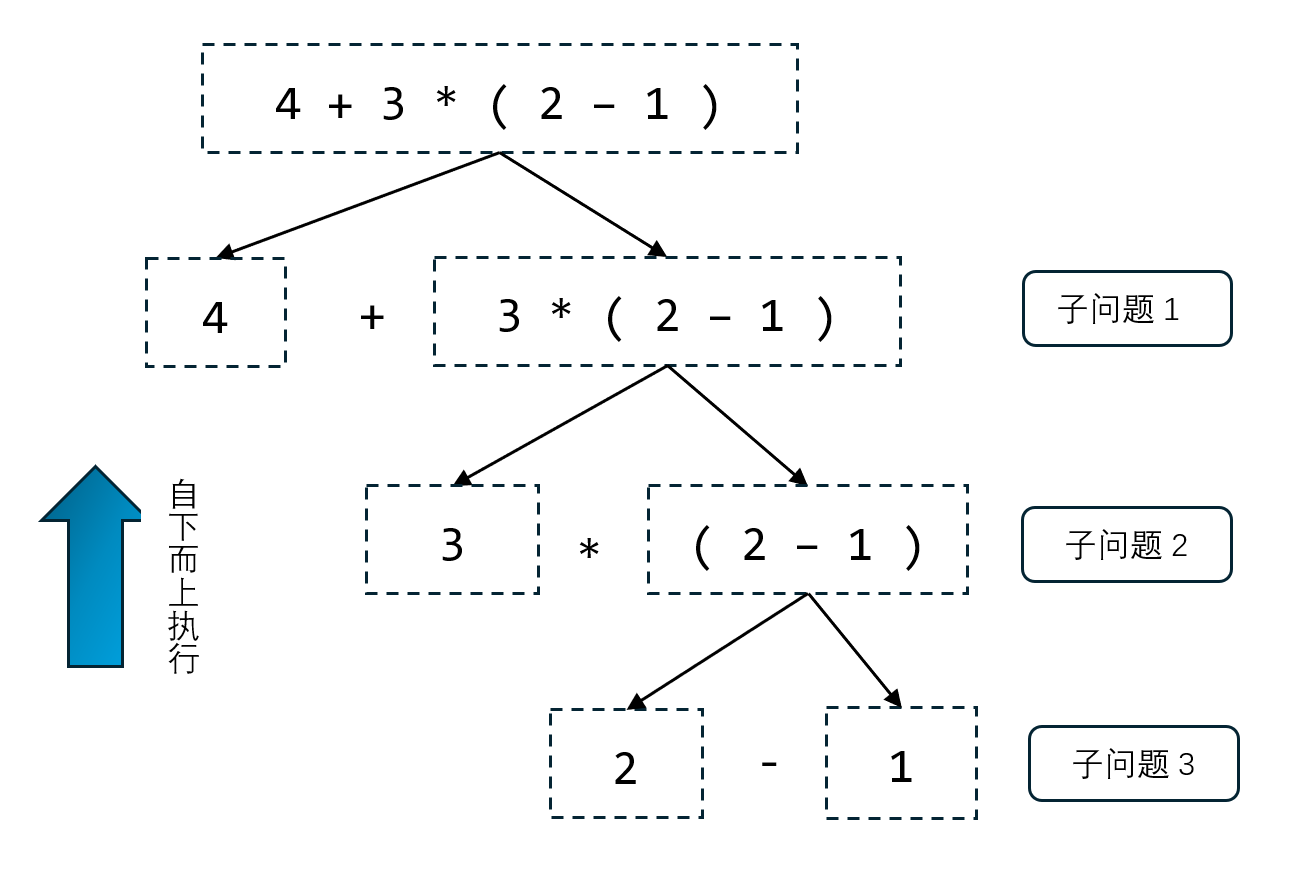
分治法求表达式的值
expr函数
1uint32_t expr(char *e, bool *success) {
2 if(!make_token(e)) {
3 *success = false;
4 return 0;
5 }
6
7 /* TODO: Insert codes to evaluate the expression. */
8
9 int i;
10 for (i = 0; i < nr_token; i++){
11 if (tokens[i].type == '*' && (i == 0 || (tokens[i - 1].type != NUM && tokens[i - 1].type != HEX && tokens[i - 1].type != ')'))){
12 tokens[i].type = POINT;
13 }
14 if (tokens[i].type == '-' && (i == 0 || (tokens[i - 1].type != NUM && tokens[i - 1].type != HEX && tokens[i - 1].type != ')'))){
15 tokens[i].type = NEG;
16 }
17 }
18 return eval(0, nr_token - 1);
19
20 // panic("please implement me");
21 return 0;
22}
- 最终实现
在/nemu/src/monitor/debug/ui.c中写入cmd_p函数:
1static int cmd_p(char *args) {
2 bool *success = false;
3 int result = 0;
4 result = expr(args, success);
5 if(!success) {
6 printf("%d\n", result);
7 }
8 return 0;
9}
表达式求值功能正式实现。
选做任务:实现负数运算和指针解引用
在eval函数中加入以下内容:
1uint32_t eval(int p, int q) {
2
3 ...
4
5 // 正常表达式
6 else {
7 // 处理一元运算符
8 else if (op == -1) {
9
10 ...
11
12 // 处理带负数的表达式,如 1+ -1
13 if (tokens[p].type == NEG) {
14 sscanf(tokens[q].str, "%d", &result);
15 return -result;
16 }
17
18 // 实现指针解引用
19 else if (tokens[p].type == POINT) {
20 if (!strcmp(tokens[p + 2].str, "$eax")){
21 result = swaddr_read(cpu.eax, 4);
22 return result;
23 }
24
25 // 其余寄存器采用类似操作
26
27 ...
28 }
29 }
30 }
31}
监视点
- 新建监视点
在nemu/src/monitor/debug/watchpoint.c中,定义函数new_wp():
1// 从free_链表中返回一个空闲监视点
2WP* new_wp() {
3 WP *temp;
4 temp = free_; // free_链表的头节点作为返回值
5 free_ = free_->next; // free_链表的下一个节点成为头节点
6 temp->next = NULL; // 空闲监视点为head链表的尾节点
7
8 // 若head链表为空,返回的节点成为头节点
9 if(head == NULL) {
10 head = temp;
11 }
12 // head链表不为空,寻找其尾节点
13 else {
14 WP *p;
15 p = head;
16 // 将返回的节点插入head链表的尾部
17 while (p->next != NULL) {
18 p = p->next;
19 }
20 p->next = temp;
21 }
22 return temp;
23}
示意图如下:
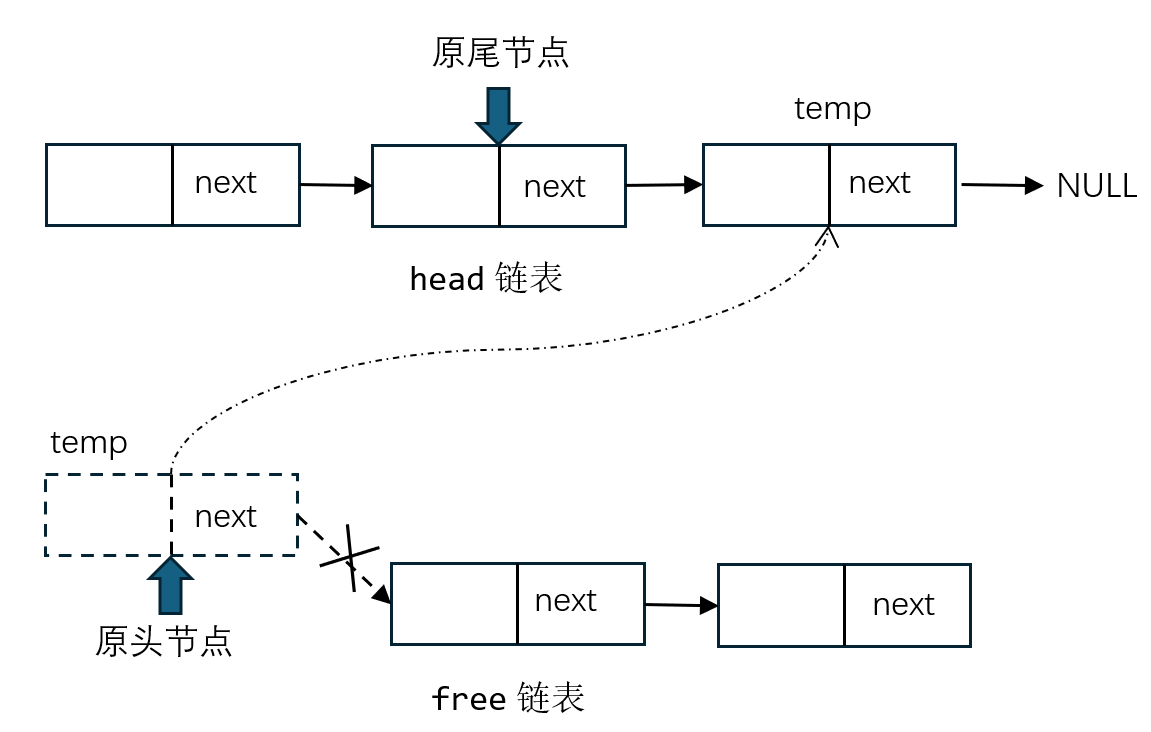
监视点链表
- 释放监视点
同理,在nemu/src/monitor/debug/watchpoint.c中定义:
1// 释放监视点至free_链表
2void free_wp(WP *wp) {
3 if(wp == NULL) {
4 assert(0); // 返回节点为空
5 }
6 else if (wp == head) {
7 head = head->next;
8 }
9 else {
10 WP* temp = head;
11 // 找到head链表待删除节点的前一个节点
12 while(temp != NULL && temp->next != wp) {
13 temp = temp->next;
14 }
15 // 取消待删除节点与其后节点的连接
16 temp->next = wp->next;
17 }
18
19 // 待删除节点成为free链表的头节点
20 wp->next = free_;
21 free_ = wp;
22
23 // 清空待删除节点的内容
24 wp->result = 0;
25 wp->expr[0] = '\0';
26}
释放监视点实际上就是新建监视点的逆操作,换言之,就是将head链表待删除的节点变成free链表的头节点。
- 判断监视点是否触发
在nemu/src/monitor/debug/watchpoint.c中定义:
1// 判断监视点是否触发
2bool checkWP() {
3 bool check = false; // 最终返回值
4
5 bool *success = false;
6 WP *temp = head; // 从head链表的头节点开始遍历
7 int expr_temp;
8
9 while(temp != NULL) {
10 expr_temp = expr(temp->expr, success);
11 if (expr_temp != temp->result){
12 check = true;
13 printf ("Hint watchpoint %d at address 0x%08x\n", temp->NO, cpu.eip);
14 temp = temp->next;
15 continue;
16 // 检测到监视点对应的值发生变化
17 }
18 temp->result = expr_temp;
19 temp = temp->next;
20 }
21 return check;
22}
在/nemu/src/monitor/cpu-exec.c中加入以下内容:
1/* TODO: check watchpoints here. */
2
3// 链接外部函数
4extern bool checkWP();
5bool change = checkWP();
6if (change) {
7 nemu_state = STOP;
8}
- 打印监视点和删除监视点
1// 打印所有监视点
2void printf_wp(){
3 WP *temp = head;
4 if (temp == NULL){
5 printf("No watchpoints\n");
6 }
7 while (temp != NULL){
8 printf("Watch point %d: %s\n", temp->NO, temp->expr);
9 temp = temp->next;
10 }
11}
12
13// 删除监视点
14WP* delete_wp(int p, bool *key){
15 WP *temp = head;
16 while (temp != NULL && temp->NO != p){
17 temp = temp->next;
18 }
19 if (temp == NULL){
20 *key = false;
21 }
22 return temp;
23}
- 加入调试器指令
最后在/nemu/src/monitor/debug/ui.c中加入指令函数:
1// 打印监视器的值
2static int cmd_info(char *args) {
3 char *arg = strtok(NULL, " "); // 获取第二个字符
4
5 ...
6
7 else if(*arg == 'w') {
8 extern void printf_wp();
9 printf_wp();
10 }
11
12 ...
13
14 return 0;
15}
16
17// 设置监视点
18static int cmd_w(char *args) {
19
20 extern WP* new_wp();
21 WP* temp = new_wp();
22
23 bool *success = false;
24 int result = 0;
25 result = expr(args, success);
26
27 if(!success) {
28 // 若表达式合法,将对应的值赋给temp这个新监视点
29 temp->result = result;
30 strcpy(temp->expr, args);
31 }
32
33 return 0;
34}
35
36// 删除监视点
37static int cmd_d(char *args) {
38 int p = 0;
39 bool key = true;
40 sscanf(args, "%d", &p);
41
42 // 记得链接外部函数
43 extern WP* delete_wp();
44 extern void free_wp();
45 WP *q = delete_wp(p, &key);
46
47 if (key){
48 printf("Delete watchpoint %d: %s\n", q->NO, q->expr);
49 free_wp(q);
50 return 0;
51 }
52 else {
53 printf("No found watchpoint %d\n", p);
54 return 0;
55 }
56
57 return 0;
58}
思考题
思考题1:opcode_table到底是一个什么类型的数组?
解答
opcode_table数组是一个函数指针数组。
思考题2(1):在cmd_c()函数中, 调用cpu_exec()的时候传入了参数-1 , 你知道为什么吗?
解答
-1是无符号类型最大的数字,所以函数里的
for循环可以执行所有指令。
思考题2(2):框架代码中定义wp_pool等变量的时候使用了关键字static,static在此处 的含义是什么? 为什么要在此处使用它?
解答
static在此处的含义是静态全局变量,该变量只能被本文件中的函数调用,并且是全局变量,而不能被同一程序其他文件中的函数调用,使用static是为了避免它被误修改。
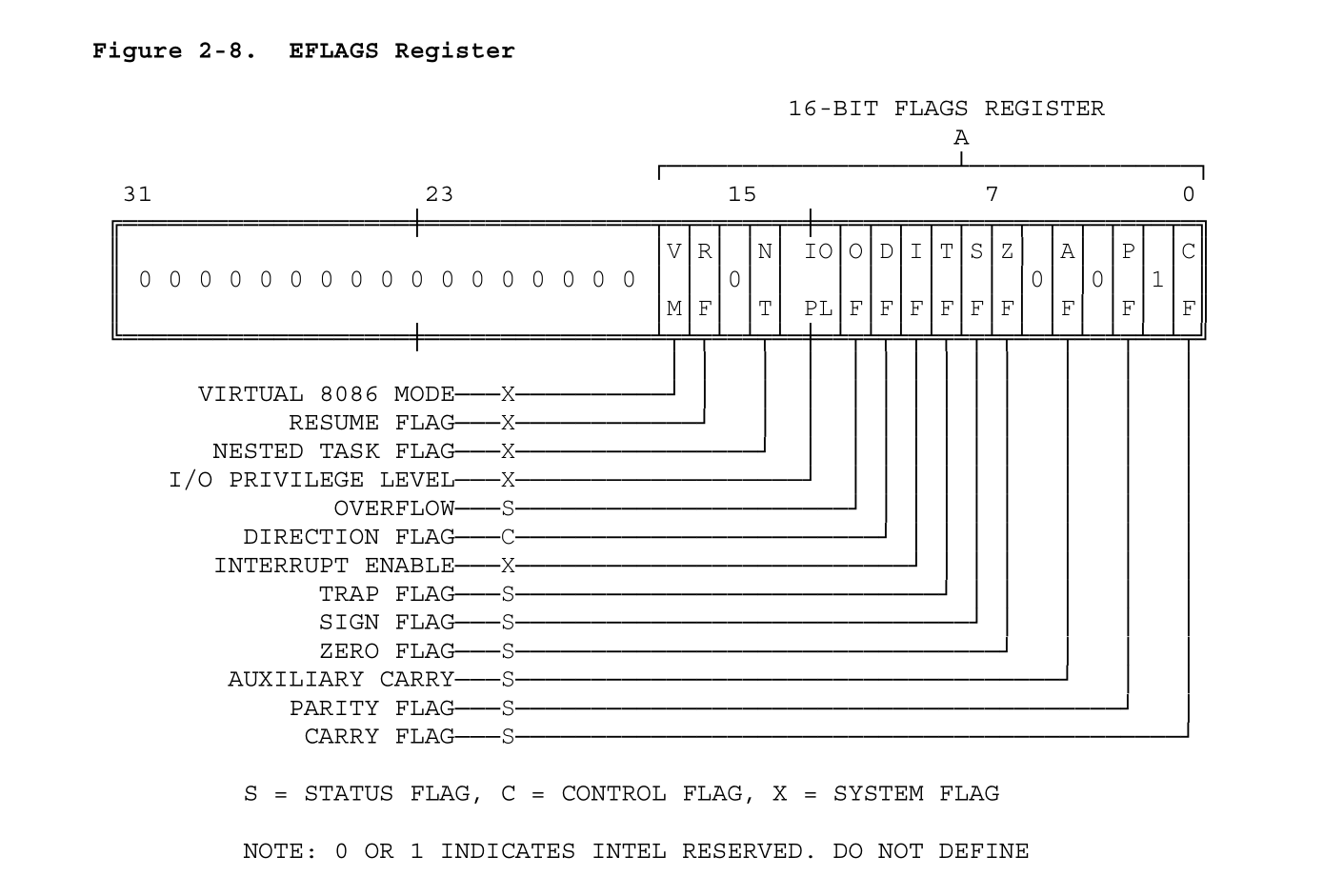
思考题3-1:EFLAGS寄存器中的CF位是什么意思?
解答
i386手册里P34页中和参阅附录c提到,CF是进位标志。
EFLAGS寄存器
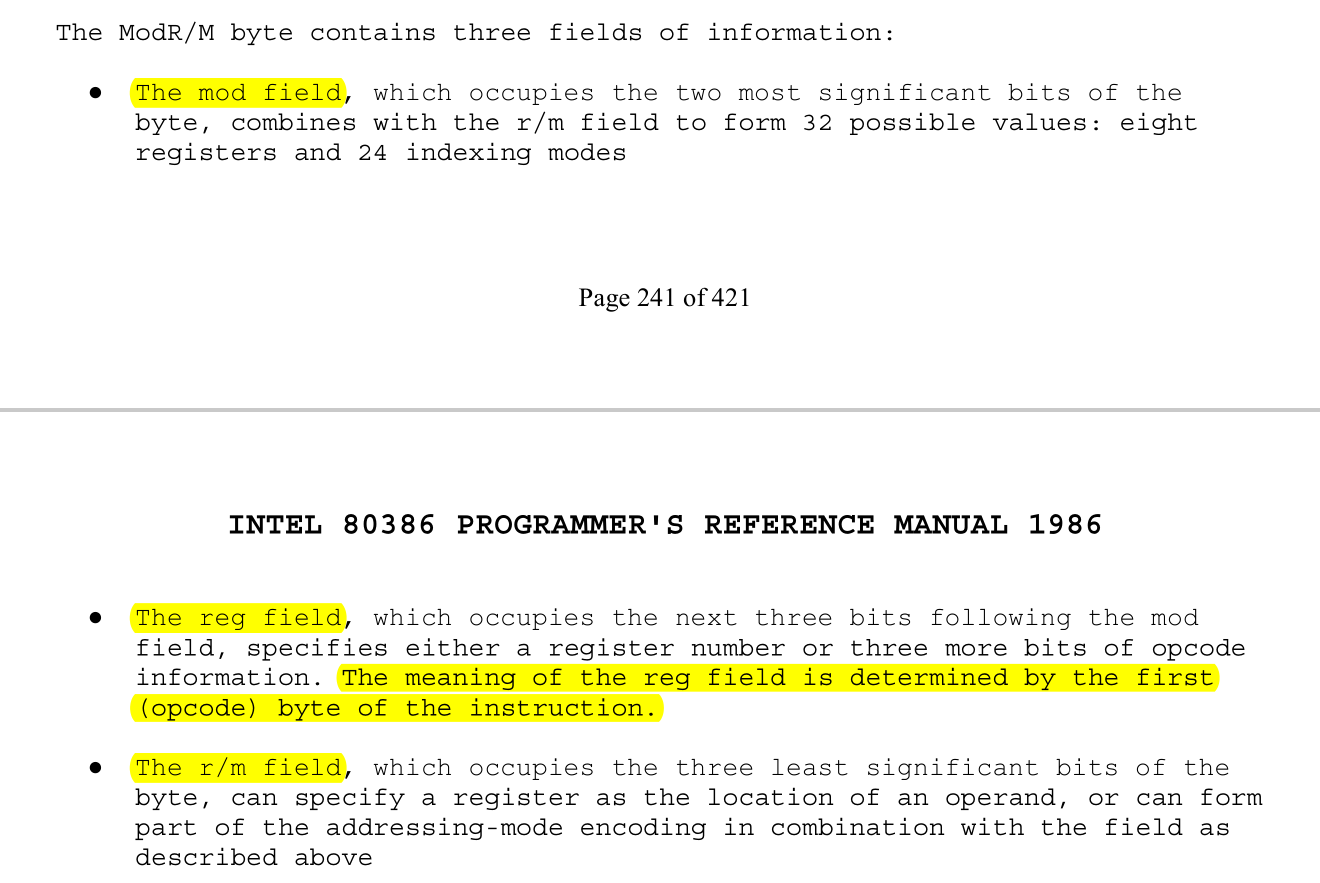
思考题3-2:ModR/M字节是什么?
解答
P241-243页。ModR/M 由 Mod,Reg/Opcode,R/M 三个部分组成。 Mod 是前两位,提供寄存器寻址和内存寻址, Reg/Opcode为3-5位,如果是Reg表示使用哪个寄存器,Opcode表示对group属性的Opcode进行补充; R/M为6-8位,与mod结合起来会得到8个寄存器和24个内存寻址。
ModR/M
思考题3-3:mov指令的具体格式是怎么样的?
解答
P345页,格式是DEST ← SRC。
mov指令

思考题3-4: 完成 PA1 的内容之后, nemu目录下的所有.c和.h和文件总共有多少行代码? 你是使用什么命令得到这个结果的?和框架代码相比, 你在PA1中编写了多少行代码?你可以把这条命令写入Makefile中, 随着实验进度的推进, 你可以很方便地统计工程的代码行数, 例如敲入 make count就会自动运行统计代码行数的命令。再来个难一点的, 除去空行之外, nemu目录下的所有.c和.h文件总共有多少行代码?
解答
通过
find . -name "*[.h/.c]" | xargs wc -l命令,得到4376行。和框架代码4197行相比, 我在 PA1中编写了606行代码。通过
find . -name "*[.h/.c]" | xargs grep "^." | wc -l命令计算去除空行的所有.c .h文件得到了3900行代码。make count指令如下:
make count
@find nemu/ -name “.c” -o -name “.h” | xargs cat | grep -v ^$$ | wc -l
思考题3-5:打开工程目录下的Makefile文件, 你会在CFLAGS变量中看到 gcc 的一些编译选项。请解释 gcc 中的-Wall和-Werror有什么作用? 为什么要使用-Wall和-Werror?
解答
-Wall使GCC编译后显示所有的警告信息。-Werror会将将所有的警告当成错误进行处理,并且取消编译操作。使用-Wall和-Werror就是为了找出可能存在的错误,尽可能地避免程序运行出错,优化程序。
至此,PA1全部完成